先丢一个画面:把“画龙点睛”四个字切成十六块拼图,再随手撒回屏幕,普通人瞄一眼就能拼回那条龙,AI却集体宕机,像刚学认字的小孩一样抓瞎。

这不是段子,是新加坡ASTAR牵头的VYU团队最新实验里真实发生的事。

他们玩了两手狠招。
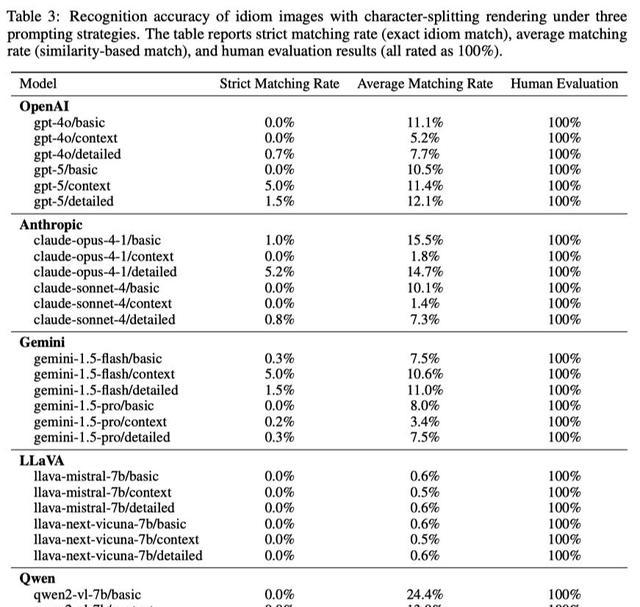
第一招,把100条成语的每个汉字横切、竖切、斜切,再打乱顺序贴回去,人类扫一眼就懂,GPT-4o、、.5 Pro、Qwen3-Max-却齐刷刷翻车,错得离谱。
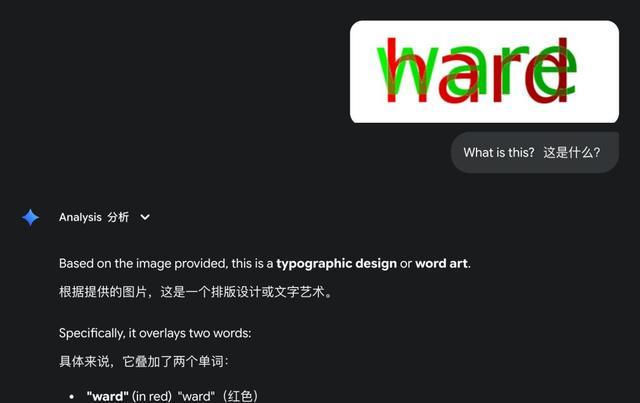
第二招更损:把“”这类八字母单词前半涂红、后半涂绿,两层颜色叠在一起,人眼自动分离,AI却像色盲一样把单词读成“”。
最尴尬的是,连最新旗舰模型也束手无策,仿佛集体忘了自己号称“多模态”。
为什么?
VYU团队一针见血:这些模型把文字当图片像素硬啃,靠模式匹配拼概率,压根没学会“偏旁部首”“字母顺序”这些人类刻在骨子里的结构知识。
一旦画面被搅乱,就像把拼图说明书撕了,AI瞬间抓瞎。
这事听着像实验室里的冷笑话,却悄悄戳中了现实痛点。
教育场景里,孩子作业本上的潦草字、历史档案里的虫蛀残页,AI可能读不出;无障碍阅读器遇到手写便条,直接罢工;更危险的是,有人故意用这招做“视觉对抗样本”,把敏感词切成碎片或叠色,AI审核系统就睁一只眼闭一只眼,放它过去。
怎么救?
VYU团队没给万能药,只递了三个方向:一是把“偏旁部首”“字母顺序”这类结构先验写进模型基因,别再让AI盲人摸象;二是训练数据里多塞点“残字”“叠色”这类脏活累活,让模型提前见世面;三是试试神经符号+图神经网络的新配方,让模型像人一样先拆结构再拼意义。
说到底,人类读书不是拍照片,而是边拆边组,边猜边认。

AI想追上这一步,得先承认自己还在看图说话的阶段,离“读书”还差一次认知革命。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...