
一条“被勒索后恢复失败”的截图在运维群炸锅,文件里躺着整整2.6TB的订单库,备份磁盘里只剩下一窝.exe。

老板当场拍桌子:一周之内把备份流程改到连黑客都看不懂。
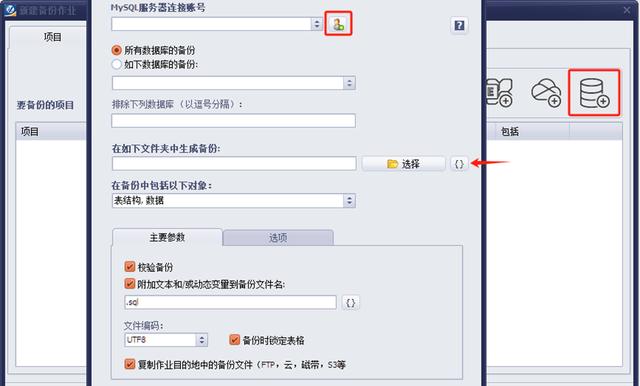
这种场景,天津鸿萌的工程师见得太多。
他们统计了2023年全年收到的应急工单:86%的MySQL故障其实不是数据库崩了,而是“备份策略崩了”。
先把坑踩遍,再说怎么爬出来。
完整备份、增量备份、差异备份听起来像数学题,说人话就是——
– 完整:把整个“抽屉”搬走,踏实,但累。
– 增量:只拿新添进来的“袜子”,省地方,恢复时得一条一条翻旧账。
-差异:介于两者,把上次完整备份之后所有“洗过的袜子”打包,恢复只跑两遍。
鸿萌老师傅的建议:日完整太大,周完整+日增量够用;如果夜里0点跑差异,早上8点交班前恢复,能把业务停机率压到一杯咖啡的时间。
怎么让不拖慢线上?
一行shell就能搞定:加个—,再加–quick,锁表时间像闪电一样短。
别迷信图形化,真正跑大规模数据的客户最后都回到脚本+管道压缩,节省的不是CPU,是运维的血压。
鸿萌自己出的“易备”不是摆设。
核心卖点:
– AES 256加密+勒索指纹比对。
只要发现可疑文件后缀,自动把备份任务挂起,邮件轰炸值班人。
– 一键发到多云:上午传到阿里云OSS,下午丢AWSS3,晚上再镜像到公司的华为云。
某电商就是靠这招,在被黑之后十分钟启动冷备,丢的只有缓存里的购物车。
恢复环节别光顾着“能不能拉起实例”,重点看能不能“拉起业务”。
有次客户以为全库恢复完事儿,结果忘了检查位置,订单状态全卡在2018年。
鸿萌提前加了校验脚本:恢复完立刻跑最频繁的那三张表的,一不一致直接回滚方案B。
监控方面,最朴素的办法最好用:备份文件大小突然掉40%,肯定出问题。
鸿萌在易备里塞进了一个“沉默警报”——连续七天备份文件size没变化,系统自动标记异常。
老板看到那条邮件提醒,连夜查岗,结果发现是备份目录权限被误改,省下一场事故。
聊到保留策略,别被“永久保留”忽悠。
天津那边有家物流企业真干过:历史订单库每季度加100G,后来一算存储费比买整台新服务器还贵。
易备给他们设了七层TTL:本地15天、OSS三个月、冷存一年,法律要求的那部分单独放到 ,账单打对折。
分片以后备份麻烦?
鸿萌的怪招:用备份节点拉取逻辑备份,把每个分片拆成独立文件。
真恢复的时候只拉坏掉的“那一罐奶粉”,其它节点继续跑,业务不掉链子。
最后,想提醒一点:别把“自动化”理解成“没人管”。
自动脚本再智能,也只能复制昨天的策略。
真遇到新业务上线、字段暴涨、表结构变更,还是得上人去验证备份能不能用。
有人说:备份这玩意,希望永远用不上,用得上的那一次一定值回所有投入。
你怎么看?

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


![[开源]一个以模块化为核心的无代码开发平台,集PC和APP快速开发](https://xcdaohang.cn/wp-content/uploads/2025/09/1759008881988_0.png)

暂无评论...