
别再只把当“会聊天”的工具了:一个能订票、记偏好、还会主动行动的隐形AI助手,正悄悄把你的琐事接管走
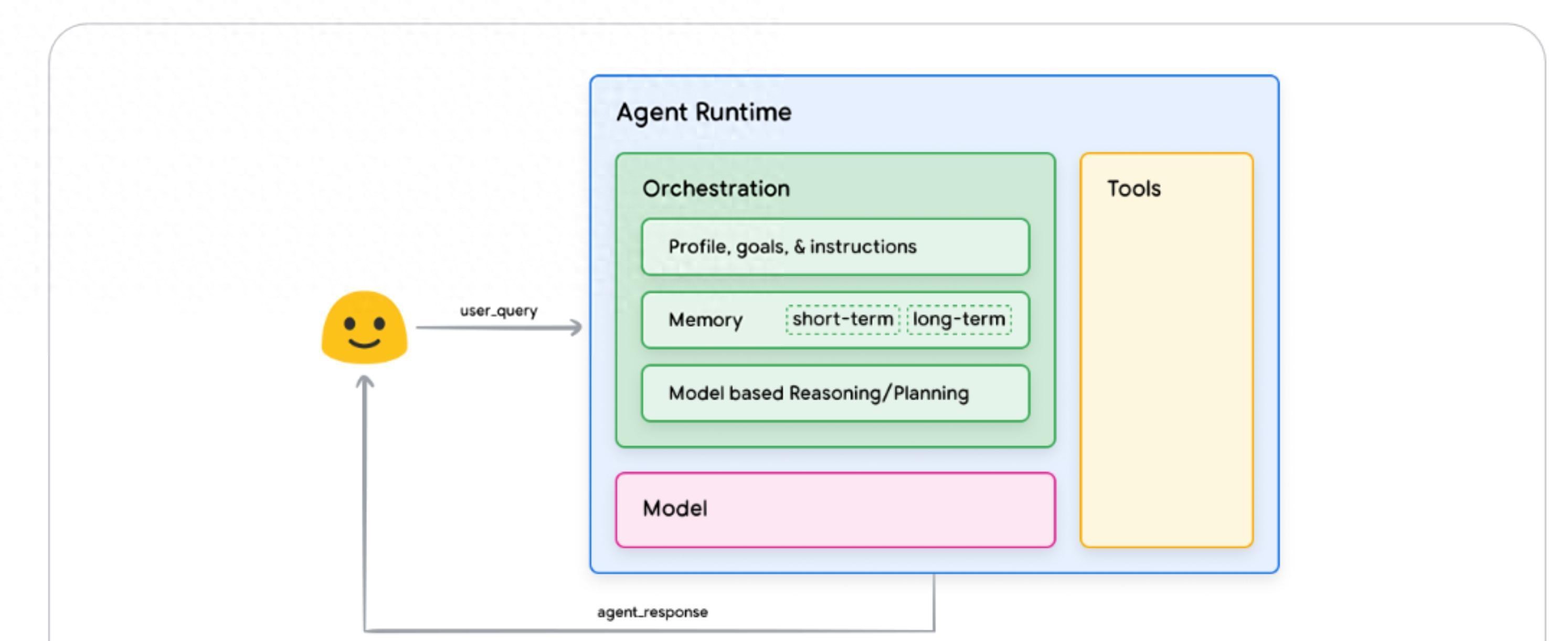
早上起床,你打开手机查天气、订高铁票、让AI推荐网红餐厅,这些看似零散的小动作,其实正是最擅长的活儿。说实话,我也被它馋到了——它不是只会回答问题的聊天机器人,而是能连外部服务、规划步骤并主动执行任务的“能干助手”。你可以把它想象成“大脑+手脚+指挥官”,大脑负责想,手脚负责做,指挥官负责安排每一步,这三样东西缺一不可。
很多人分不清和普通生成式模型的区别,简单来说,式的模型更像“知识丰富的学生”,能给建议却不会动手,而是真正会去执行的人。打个生活例子:普通模型可能会告诉你“去杭州周末可以逛西湖”,但会主动查当天的天气、比对高铁时刻、评估餐厅是否有座位,然后把最优方案呈现给你,有条件的话还可以直接帮你下单订票。
靠三类“工具”扩展能力。就像开了直接调用外部API的快捷入口,适合实时查天气或航班;更像是让AI下发“执行指令”交给你方的系统来把关,适合涉及钱和权限的操作;Data 则是给装了一个私人图书馆,便于它查阅公司手册或你的历史偏好。比如我朋友小李用Data 把家里旅行偏好和孩子的过敏信息放进去,结果能给出既省钱又安全的亲子行程,节省了他好几个小时的对比工作。
学习怎么用工具,也有不同策略。上下文学习像临时偷师,适合短期新工具快速上手;检索式上下文学习像把操作步骤写进笔记本,需要搭建例子库;微调则像系统培训,适合企业把常用流程训练成长记忆。我同事张姐的团队就用了检索式方法,把常见审批和报销模板放进例子库,客服响应速度立刻提升,错误率也下降不少。
当然,便利背后有问题不能忽视,说白了就是安全与责任问题。去年一个案例里,公司把订票权限给了,结果因为没有人工确认阈值出现了重复预订,财务一度崩溃。教训是明确权限分层,重要操作一定要加上人工复核和日志审计;技术上要做到最小权限、加密存储和可回溯的操作记录,合规上则要明确谁为Agent的决策承担责任,这些都不是技术能单独解决的,而是技术与制度并行的事。
如果你是普通用户,我觉得可以先从“只查不改”的开始试水。先把天气、餐厅、航班这类只读权限交给它,观察一段时间它的决策可靠性再逐步增加权限;再者,使用时优先选择能提供人工确认流程的服务,遇到交易或个人敏感信息时坚持人工二次确认,这是现实又安全的折中法。开发者和企业则要在设计时把日志、审批链和回滚机制当成标配,别把“能做事”当成“就能无限制做事”的通行证。
未来的方向很直观,但也值得琢磨。会从单个助手走向“多Agent协作”的团队模式,旅行、医疗、财务场景都会看到专职的交通Agent、住宿Agent、预算Agent分工协作,这会让服务更专业但也更复杂。与此同时,隐私保护和责任认定会成为监管重点,技术上可能出现更多“本地化存储+端侧判断”的方案,让更像家电而不是厂商的眼睛。
说到底,不是要取代我们做决策的能力,而是替我们承担重复、低价值的操作,把时间还给人。不得不说,这种“有脑有手有谱的助手”听起来很香,但使用时的底线和信任建立,决定了它是帮你忙还是添麻烦。你有没有试过让AI代你处理哪件日常琐事?那些让你满意或者后悔的细节是什么,愿意分享你的界限和担忧吗?
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...