
策略梯度的核心思想:获得最优策略。
算法 1: – 最简单的开始
核心思想
是最基础的策略梯度算法,思路非常直观:
有个致命问题:方差太大。就像一个学生每次考试分数波动很大,这次 90 分,超高奖励,下次 60 分,超高惩罚,导致学习过程很不稳定。
算法 2: + – 加入对比参照
解决思路:引入”参照物”
为了让学习更稳定,我们引入一个参照标准:不是看绝对分数,而是看相对表现。
核心思想:不直接使用奖励分数,而是用”奖励 – “的差值。

用考试类比理解:想象班里 5 个同学的考试成绩:
85, 75, 95, 65, 80
不用 (原始 ):
使用 (平均分 = 80):
的用处:
传统的 :
RLOO留一法的巧妙设计
RLOO 是一种特别聪明的 方法:
传统 :用所有回答的平均分
RLOO 的做法:用”其他回答”的平均分
这样做的好处:
算法 3:PPO – 更稳定的学习
PPO 要解决的问题
即使有了 ,策略梯度算法仍然可能”用力过猛”:
问题场景:
这就像开车时猛打方向盘一样危险。
PPO 的核心创新:渐进式改进
PPO 说:”我们要改进,但不能改得太激进”
关键机制:裁剪()

用开车比喻理解 PPO
想象你在学车:
PPO 的两个关键组件
价值网络(Value )
2. 裁剪机制()
PPO 完整流程

PPO 的优势如下:
算法 4:GRPO – 最新的简化方案
GRPO 的设计哲学
GRPO(群体相对策略优化)的想法是:”PPO 很好,但能不能更简单?”
PPO的”重量”:
GRPO的”轻量”:(移除了价值模型和奖励模型)
GRPO 的核心思想:群体内比较
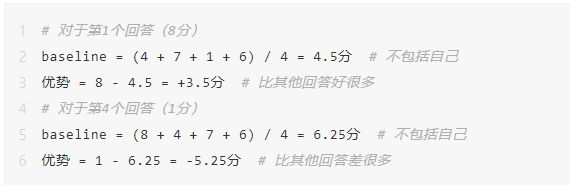
还是用考试的例子:
PPO 的做法:
GRPO 的做法:
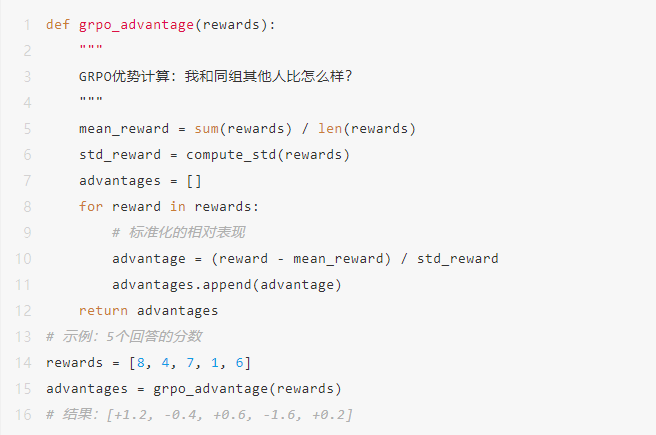
GRPO 的优势计算:
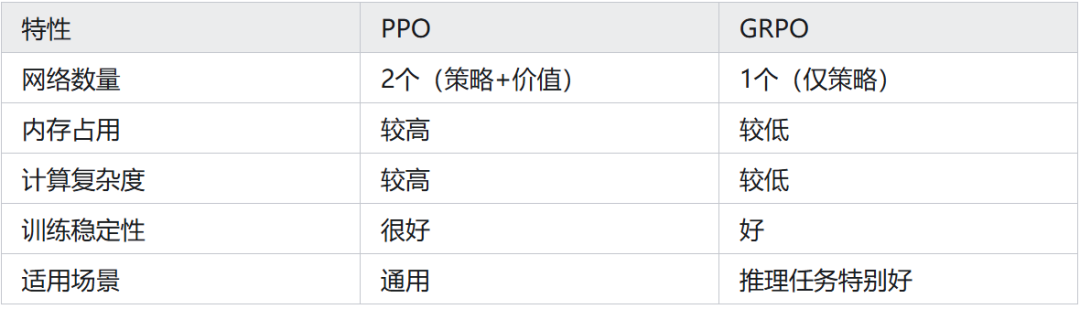
GRPO vs PPO 对比:
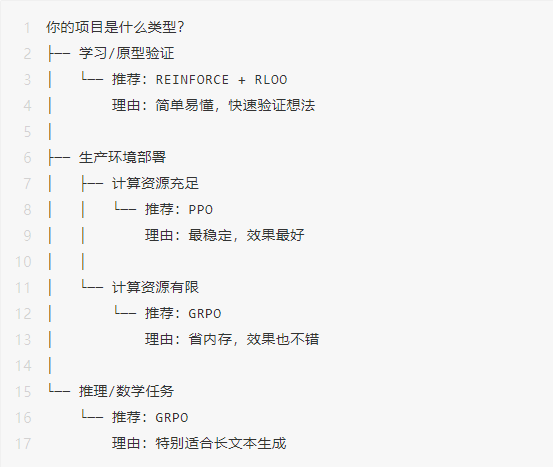

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...