
文生3D是3D AIGC的热点研究内容,近半年以来,得到了学术界和工业界的广泛关注。最近清华大学刘永进教授课题组提出一种新的文本-图像条件扩散模型(Text-Image , TICD)方法,在数据集()上达到目前的最好效果。论文已经发布在,代码即将开源。
目前主流的文本生成3D方法大多使用预训练的2D扩散模型,通过得分蒸馏采样(Score , SDS)优化神经辐射场(NeRF)来生成全新的3D模型。然而,这种预训练扩散模型提供的监督仅限于输入的文本本身,并未约束多视角间的一致性,可能会出现生成几何结构较差等问题。为了在扩散模型的先验中引入多视角一致性,一些最新的研究通过使用多视角数据对2D扩散模型进行微调,但仍然缺乏细粒度的视角间连续性。为了解决这一挑战,TICD方法将多视角图像条件纳入NeRF优化的监督信号中,保证了3D物体不同视角间的强一致性,有效提升了生成3D模型的质量。
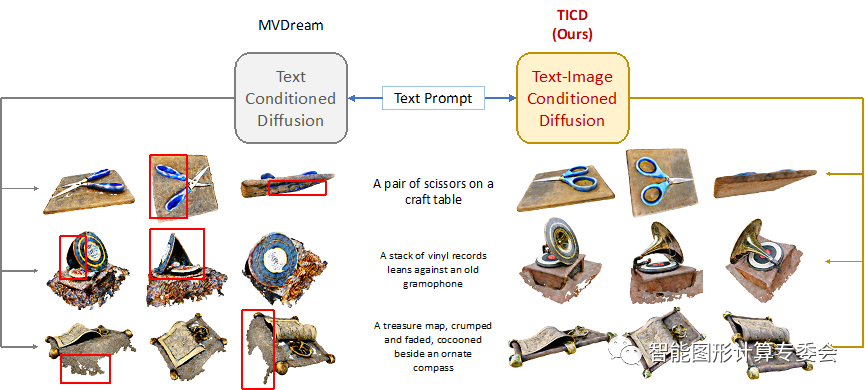
清华大学的TICD方法可以在不同层级上提升生成3D模型的质量。以文本为条件的多视角扩散模型生成符合输入文本描述的3D模型,约束3D信息的粗一致性;同时,以图像为条件的新视角扩散模型根据多个视角渲染图片之间的一致性进行3D信息的更新,使得生成3D信息具有不同视角间的强一致性。
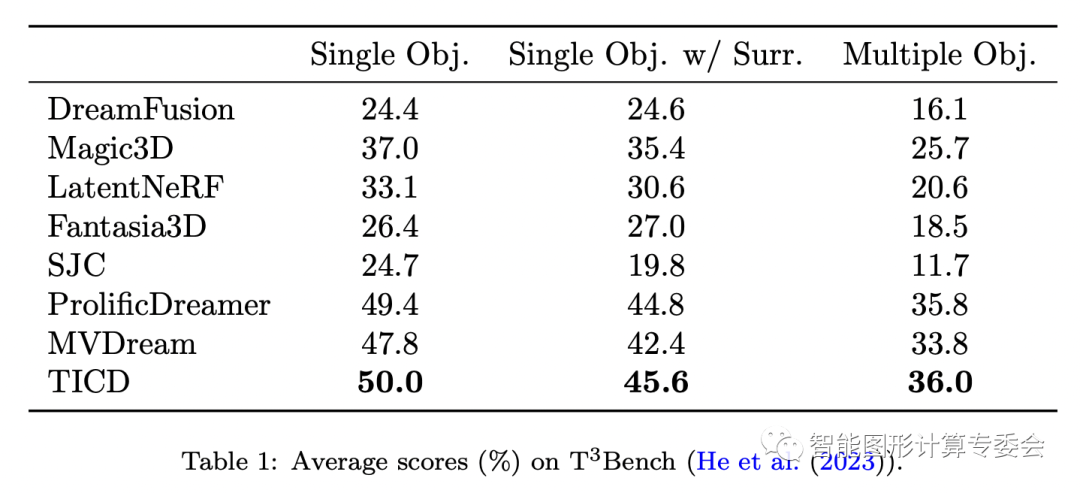
TICD方法可以有效消除现有方法面对特定文本输入时可能产生的几何信息消失、错误几何信息过量生成、颜色混淆等问题。在数据集上的定量测试评估结果表明,该方法在与现有文本生成3D方法比较中取得了最好的效果。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...