
知识蒸馏( , KD)是一种模型压缩技术,主要用于深度学习领域。其核心思想是使用一个已经训练好的大型模型(通常被称为”教师模型“)来指导或训练一个更小、更轻量级的模型(被称为”学生模型“)。通过这种方式,小模型可以从大模型中“蒸馏”出所需的知识,从而达到相对较高的性能,尽管其结构可能更为简单。
知识蒸馏的基本步骤如下:
1. 训练教师模型:首先,通常会使用大量数据训练一个大型的深度模型。这个模型由于其复杂性和规模通常能够获得很高的性能。
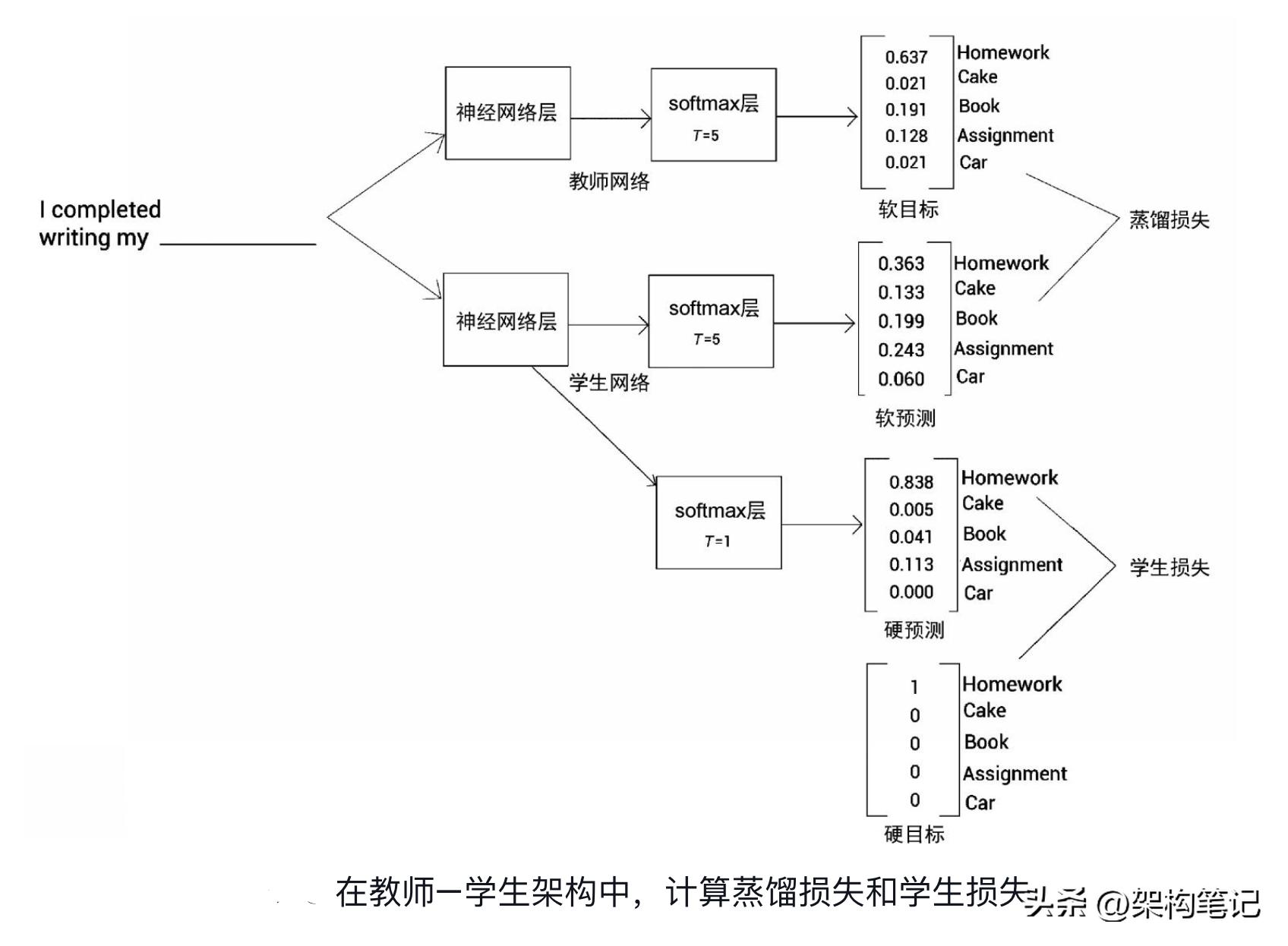
2. 蒸馏知识:然后,我们使用教师模型来指导学生模型的训练。在最简单的情况下,这可以通过将教师模型的输出(如概率)用作新的标签,来训练学生模型。教师模型的输出通常提供了比硬标签(原始数据集的标签)更多的信息,这有助于学生模型学习更为丰富的知识。
3. 使用学生模型:一旦学生模型被训练好,我们就可以在实际应用中使用它,而不再需要大型的教师模型。
知识蒸馏的主要优势包括:
知识蒸馏的一种常见策略是使用教师模型的输出的温度变种。通过增加温度,可以得到一个更加“柔和”的概率分布,这有助于传递更多的知识给学生模型。
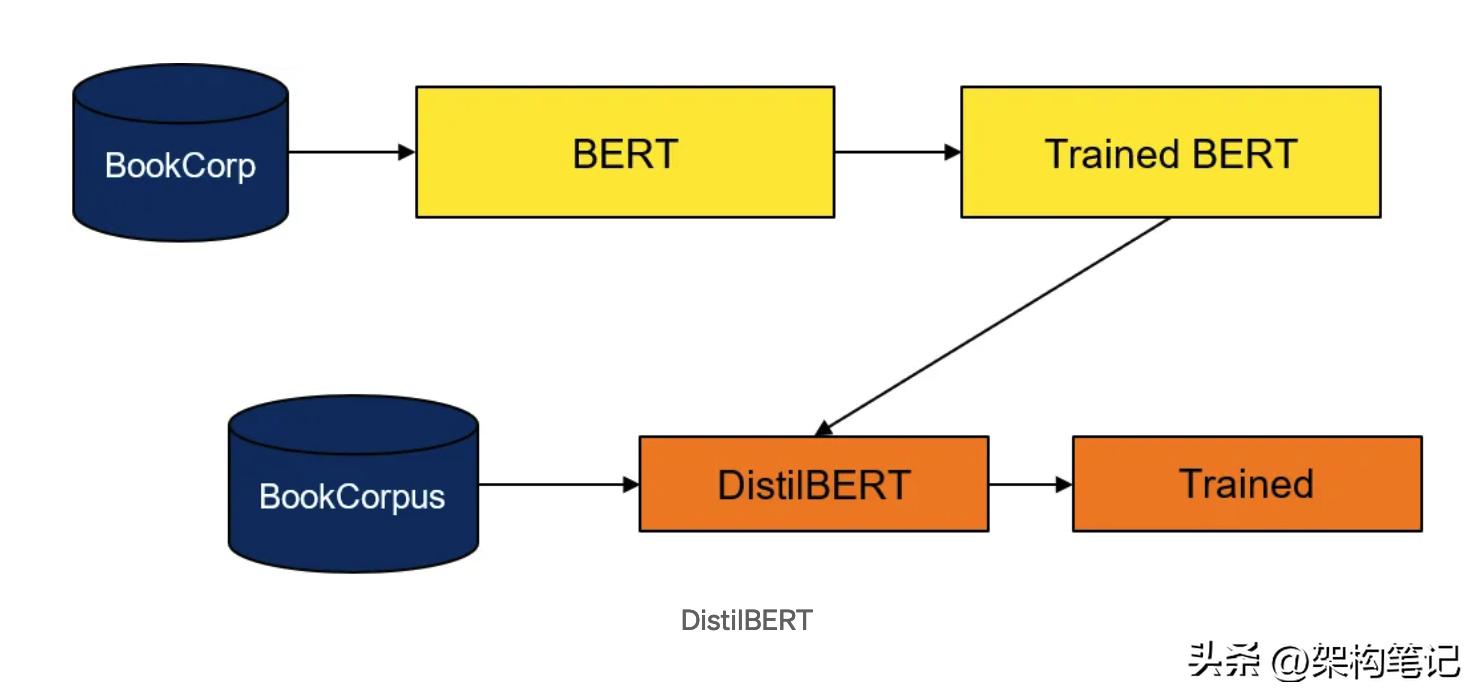
总的来说,知识蒸馏是一种强大的技术,它允许我们从大型模型中获得知识,并将其压缩到更小、更高效的模型中。
#妙笔生花创作挑战#
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...