在大规模语言模型(LLM)快速发展的今天, of (MoE, 混合专家模型) 成为一种重要的模型架构。MoE 通过引入“专家网络”与“路由器”,在保证模型表达能力的同时显著降低了计算和显存开销。然而,MoE 的训练与推理天然需要分布式集群来完成,这就涉及到 如何在多 GPU / 多机器环境下高效部署与调度。本文总结了 MoE 分布式推理的核心机制,并结合“微服务架构”进行类比,帮助大家从工程视角理解 MoE 的运行原理。
1. MoE 的基本结构
换句话说,MoE 就像是一个“专家团队”, 负责把不同问题分派给合适的专家处理。
2. MoE 的分布式推理2.1 专家并行( )
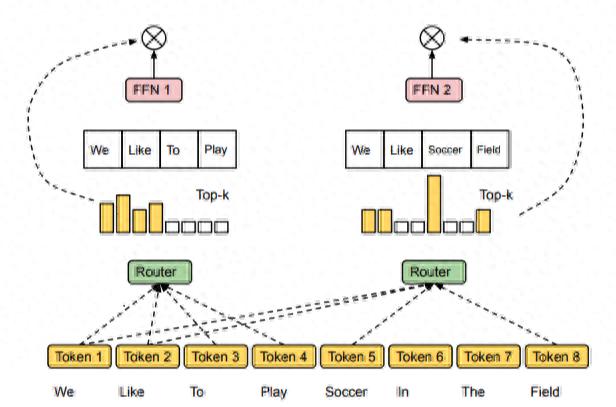
在 MoE 的分布式部署中,并不是在每张 GPU 上放置完整的专家集合,而是采用 专家并行:
2.2 Token 的分发与通信 决策:每个 token 经过 网络,得到要走的专家编号。 分桶:将属于不同专家的 token 重新分组。All-to-All 通信:每个 GPU 将需要其他 GPU 处理的 token 发送过去,并接收别的 GPU 发来的 token。专家计算:各 GPU 上的专家处理分配到的 token。结果回传:计算结果再通过 all-to-all 回传,拼装成原始顺序。
这种流程保证了即使专家被拆分在不同 GPU 上,整体模型依然可以作为一个函数正常工作。
2.3 权重的存储与加载3. MoE 与微服务架构的类比
从工程视角,MoE 的运行方式和微服务架构有很多相似之处:
对比维度
MoE
微服务架构
功能单元
专家网络()
独立服务()
调度机制
决定 token 去哪个专家
API 网关/调度器决定请求去哪
实例分布
各 GPU 只存部分专家
各实例只实现部分业务功能
通信方式
All-to-All 跨 GPU 通信
RPC / HTTP 服务调用
目标
减少显存和计算量
解耦业务、提升扩展性
换句话说,传统大模型 = 单体应用,MoE = 模型层面的微服务架构。
4. 总结
这种理解不仅有助于把握 MoE 的技术细节,也能帮助工程师从分布式系统和微服务的角度更好地思考大模型的部署方式。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...