所谓的无限宽度( width),指的是完全连接层中的隐藏单元数,或卷积层中的通道数量有无穷多。
虽然这些理论结果只是在无限宽度条件下成立,但谷歌发现原始网络的预测与线性版本的预测之间的一致性极好。而且对不同的体系结构、优化方法和损失函数都适用。
随着网络宽度变大,神经网络可以被其初始化参数的一阶泰勒展开项所取代。 而一阶线性模型动态的梯度下降是可解析的。
我们将这项研究的内容简单介绍如下:
实验方法
本文采用完全连接、卷积和宽体系结构,使用足够小的学习速率,用完全和小批(mini-batch)梯度下降来训练模型,对比原始模型和线性模型之间的差异。
最后在CIFAR-10 (马和飞机)上进行二元分类,以及在MNIST和CIFAR-10上进行十种分类。
理论原理
在高等数学中,有一种叫做“牛顿法”的方程近似解法。当所选区域足够小,就能用直线代替曲线,即一阶泰勒展开求近似解。在神经网络中,也有这么一种方法。
对于任何神经网络参数都可以做泰勒展开,即初始值加无限的多项式形式。当网络层的宽度趋于无限的时候,只需要展开中的第一个线性项,就成了线性模型。
假设D是训练集,X和Y分别表示输入和标注。这个完全连接的前馈网络有L个隐藏层、宽度为n。
在监督学习中,通过参数θ最小化经验损失,它是一个随时间变化的参数。f为输出的。
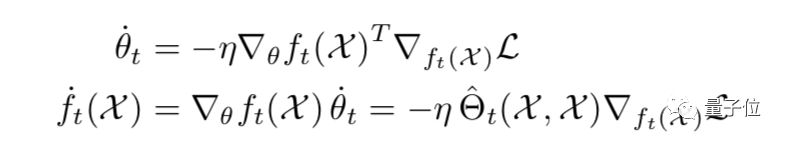
线性化网络
我们将神经网络的输出做一阶泰勒展开:
ωt定义为θt − θ0,即参数θ相对于初始值的变化。输出包含两个部分,第一项是神经网络输出的初始值,在训练过程中不会改变;第二项是训练过程中的改变量。
ωt和ft随时间的变化满足以下常微分方程(ODE):
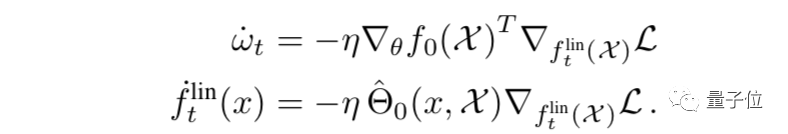
无限宽度的高斯过程
随着隐藏层宽度的增加,更加统计学中的中心极限定理,输出的分别将趋于高斯分布。
f(x)的平均值和标准差满足以下方程:
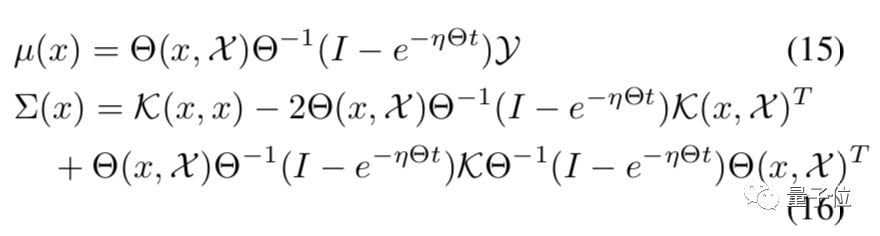
结果讨论
当宽度无限且数据集有限时,神经网络的训练动态与线性化的训练动态相匹配。
在以前的实验中,选择足够宽的网络,能实现神经网络和较小数据集线性化之间较小的误差。
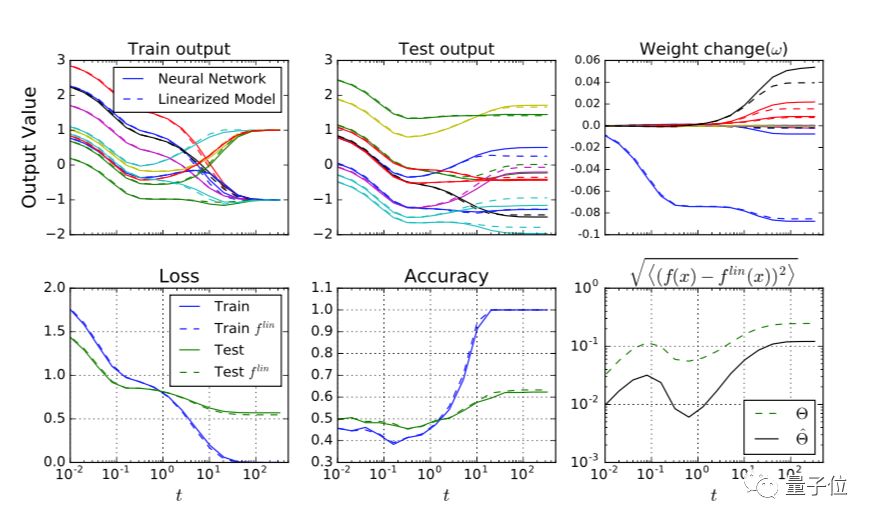
谷歌研究了如何在在模型宽度度和数据集大小在相当大的一个取值范围内,让线性化动态和真实动态之间取得一致性。
最终,谷歌考察了测试集上网络的预测输出和真实输出之间的均方根误差( RMSE )。RMSE会随着时间的推移而增加,直到训练结束时达到某个最终值。
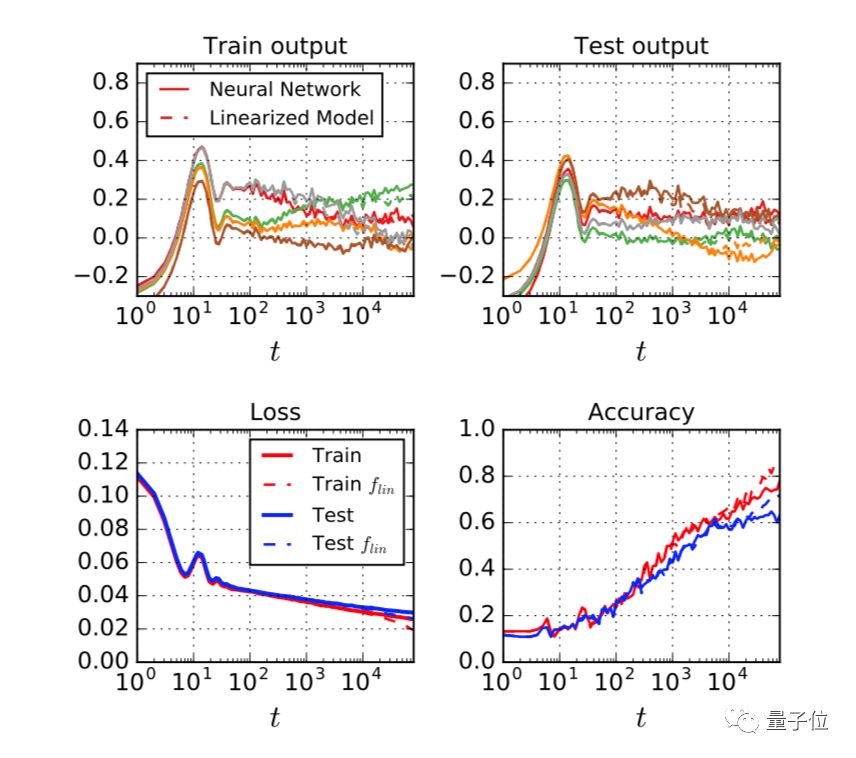
我们可以看出,随着网络宽度的增加,二者之间的误差逐渐减小。对于全连接网络来说,这种下降的速率大约为1/N,对于卷积和WRN体系结构来说,则下降的比例更为模糊。
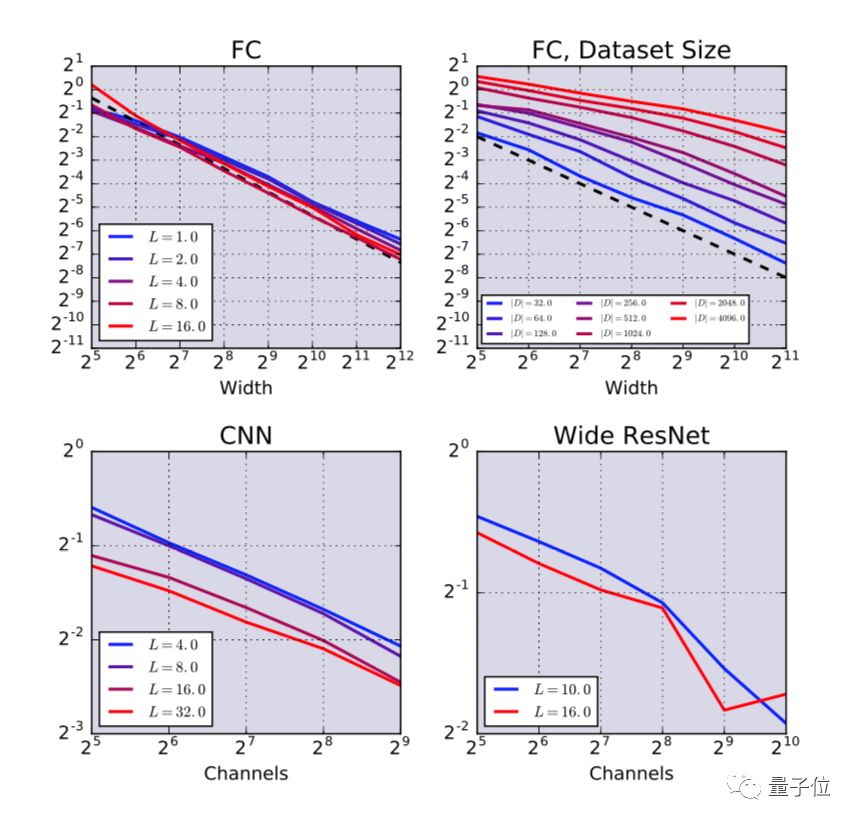
此外,我们还可以看出,误差随着数据集大小,呈近似线性增长。尽管误差随着会数据集增加,但可以通过相应地增加模型大小来抵消这一点。
作者系网易新闻·网易号“各有态度”签约作者
— 完 —
加入社群
量子位现开放「AI+行业」社群,面向AI行业相关从业者,技术、产品等人员,根据所在行业可选择相应行业社群,在量子位公众号()对话界面回复关键词“行业群”,获取入群方式。行业群会有审核,敬请谅解。
此外,量子位AI社群正在招募,欢迎对AI感兴趣的同学,在量子位公众号()对话界面回复关键字“交流群”,获取入群方式。
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号()对话界面,回复“招聘”两个字。

量子位 · 头条号签约作者
վ’ᴗ’ ի 追踪AI技术和产品新动态
喜欢就点「好看」吧 !
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...