
上篇文章以-R1为例,我们介绍了什么是量化,不同量化版本的差距是什么。
这篇我们来了解下什么是上下文窗口以及不同量化方式、上下文下的显存占用估算。
为什么有的模型回答会被截断?
有时候我们在一个窗口发送了许多内容的时候模型还没有思考完成,但是后续就不再继续输出了,这是因为模型回答已经达到了其“最长输出”的上限。对于 的官方 API 来说,最大思维链长度为 32K,最大输出为 8K,就其原始模型来说,最大可以提供约 164K 的上下文,也就是大约能理解和输出总和差不多 10~16 万字。但在提供超长上下文的背后其实是大量的资源消耗,因此一些 API 可能不会开放最大的输出和上下文能力。对于以往的大部分非推理模型来说,可能 4K 的上下文足以满足单次对话的需求,但是对于推理模型来说,由于“思考”需要占用上下文,因此 4K 上下文可能连单次会话都不够用,对于用户使用产生明显的困扰。
什么是模型的上下文窗口?
上下文窗口指模型在一次推理过程中能够处理的最大 Token 数量,平均一个 Token 能对应多少汉字对于不同的模型略有区别。上下文长度越长,模型能够记忆和理解的文本信息就越多,这对于长文本生成和复杂任务处理尤为重要,特别是较大规模的代码生成、专业内容的理解分析等。
上下文长度对模型效果的影响
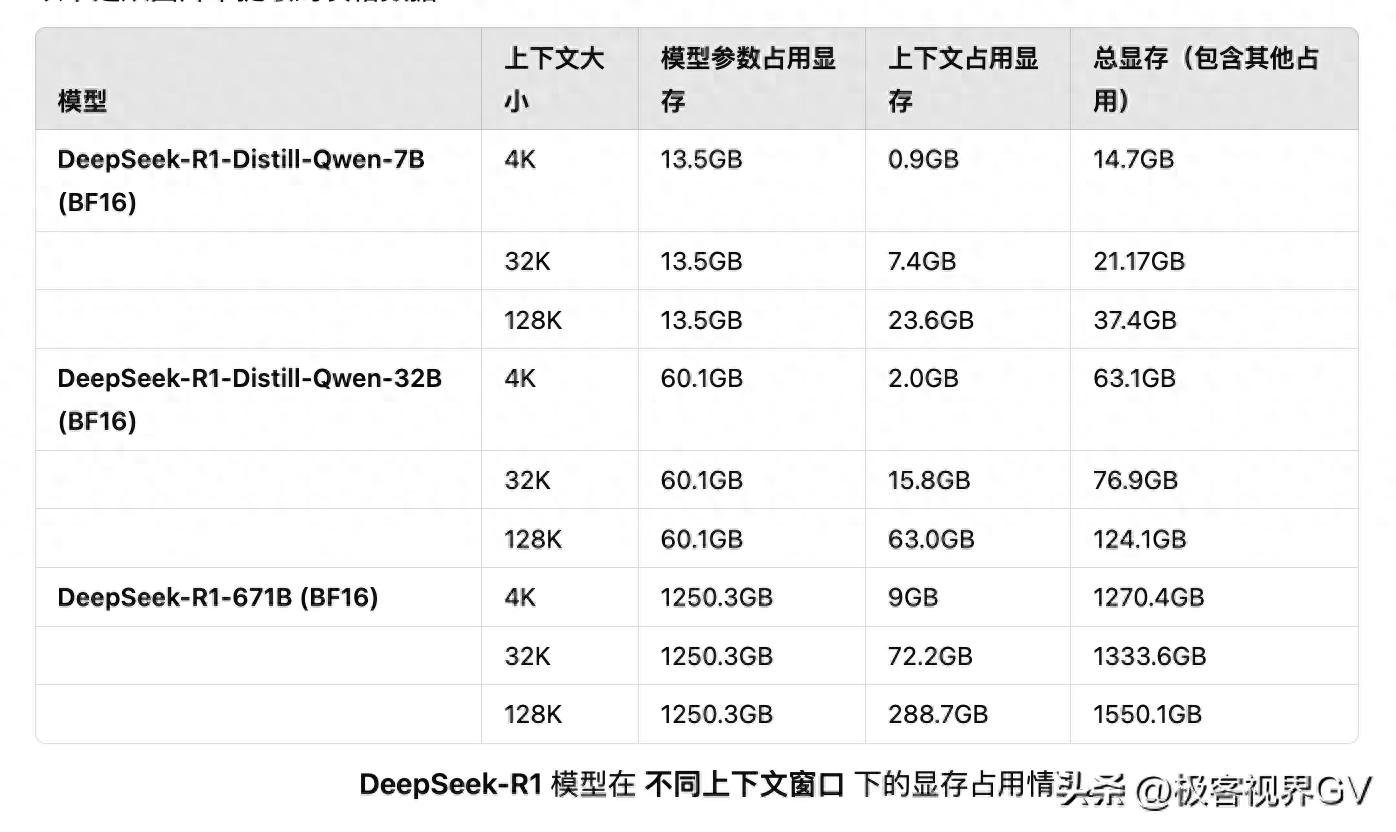
显存大小如何估算
模型的显存占用主要由以下部分组成:
1. 模型参数: 与模型的参数量和精度有关。
2. KV Cache: 与上下文长度、批次大小和注意力头数量有关,此外,和推理框架的内存使用方式也有关。
3. 中间计算结果: 与模型结构和输入数据有关。
相关各类模型规模和量化方式下的显存需求概览
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...