大模型正在与我们的生活形成愈发紧密的联系,那么,我们怎么理解大模型背后的底层逻辑?不妨来看看本文的拆解。

随着人工智能技术的突飞猛进,大语言模型(Large , LLM)已经从实验室走进现实生活,以其强大的自然语言理解和生成能力引领AI领域的新一轮变革。
本文将深入剖析大语言模型背后的底层逻辑,包括其基于深度学习的架构设计、复杂的训练机制以及广泛的应用场景,旨在为读者揭示这一前沿技术的核心原理和价值所在。
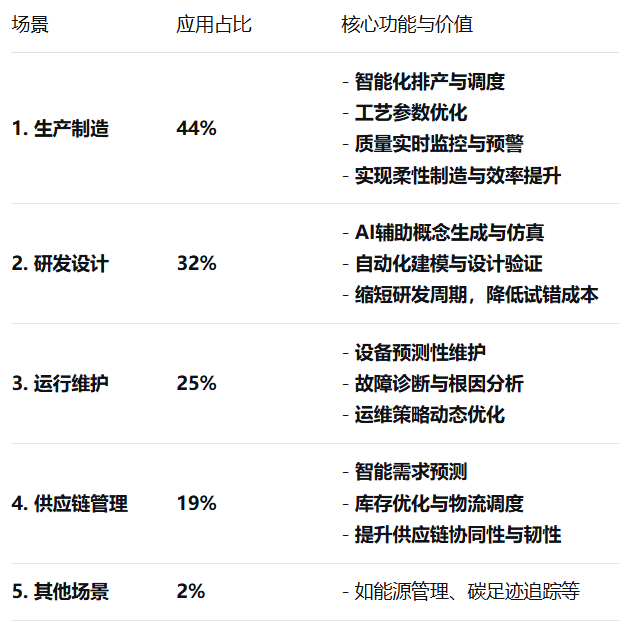
一、大语言模型的深度学习架构解析1. 词嵌入层(Token )
大语言模型首先使用词嵌入技术将文本中的每个词汇转化为高维向量,确保模型可以处理连续的符号序列。这些向量不仅编码了词汇本身的含义,还考虑了语境下的潜在关联。
2. 位置编码( )
为了解决序列信息中词语顺序的问题,引入了位置编码机制。这种机制允许模型理解并记住单词之间的相对或绝对位置关系,即使在转换成固定长度向量后也能保留上下文信息。
3. 自注意力机制(Self- )
自注意力是的核心部件,通过计算输入序列中每个位置的单词与其他所有位置单词的相关性,从而实现对整个句子的全局建模。多头自注意力则扩展了这一机制,使其能够从不同视角捕获并整合信息。
4. 前馈神经网络( , FFNs)
在自注意力层之后,模型通常会包含一个或多个全连接的FFN层,用于进一步提炼和组合特征,增强模型对复杂语言结构的理解和表达能力。
二、大语言模型的训练策略及优化技术1. 自我监督学习
利用大规模无标签文本数据进行预训练时,主要采用如掩码语言模型(MLM)或自回归模型(GPT-style)等策略。
MLM通过对部分词汇进行遮蔽并让模型预测被遮蔽的内容来学习语言表征;而自回归模型则是基于历史信息预测下一个词的概率。
2. 微调阶段
预训练完成后,模型在特定任务上进行微调以适应具体需求。这可能涉及文本分类、问答系统、机器翻译等各种下游任务,通过梯度反向传播调整模型参数,提升任务性能。
3. 先进的训练方法
进一步发展还包括对比学习,利用正负样本对强化模型识别和区分关键信息的能力;以及增强学习,使模型通过与环境交互,逐步优化其输出以最大化预期奖励。
三、大语言模型的应用场景深度探讨1. 自然语言生成2. 对话系统构建
开发具备上下文记忆、情感识别等功能的智能聊天机器人。
3. 机器翻译
实现跨语言的高质量实时翻译服务。
4. 知识抽取与推理
提取文本中的实体和关系,构建和更新知识图谱,并进行知识推理。
5. 文本理解与分析四、面临的挑战与未来展望
尽管大语言模型取得显著进步,但依然面临诸多挑战:
未来发展趋势:
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...