
“凌晨三点被电话叫醒,只因数据库告警像雪花一样刷屏,但没有一个告警告诉你真正问题在哪。

”——如果你干过运维,这句话比咖啡还提神。
别再靠堆人头救火。2023年一出,AI不再只是写PPT,已经可以钻进机房里跟你并肩熬夜。
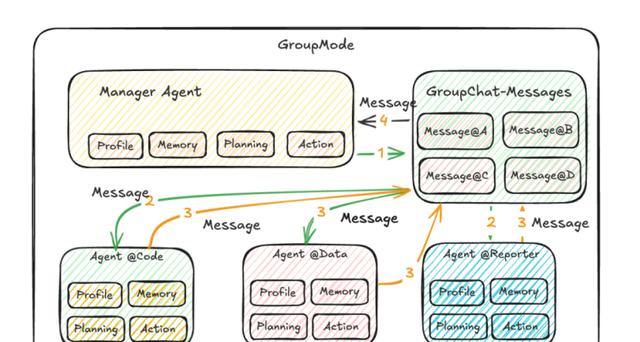
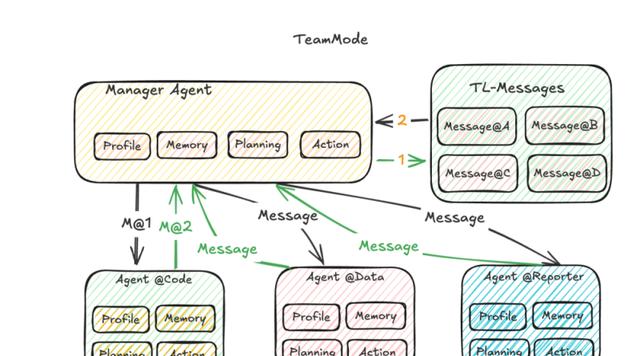
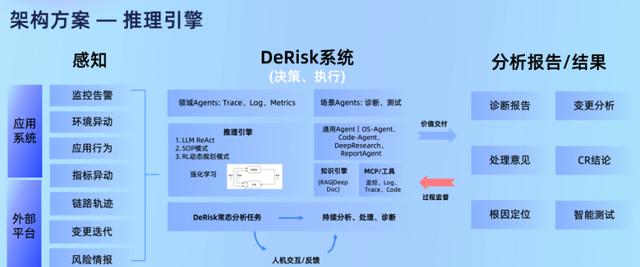
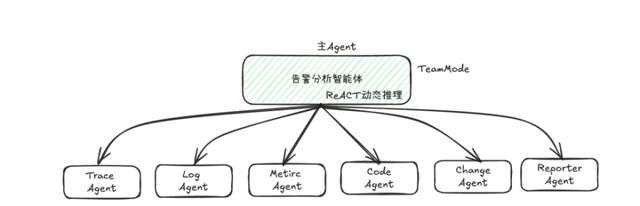
蚂蚁最近悄悄上线一个叫的多智能体系统,它的玩法简单粗暴:把告警群聊拆成若干个“专项小组”,每个小组只盯一件事,像监控指标特工、日志拆弹专家、代码洁癖狂魔,最后拉个“报告小哥”把结论拍你脸上。
效果?
版块的误报降到原来的15%,人均睡眠时间肉眼可见地回来了。
听起来像科幻?
拆解一下,你会发现门槛其实没那么高。
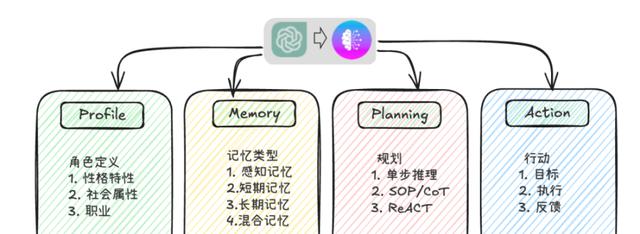
1、多智能体≠人多,而是“角色清楚、记忆在线”
系统里面每个小AI都有四格血槽:我是谁()、我手里有什么牌()、下一步打哪张牌()、出牌()。
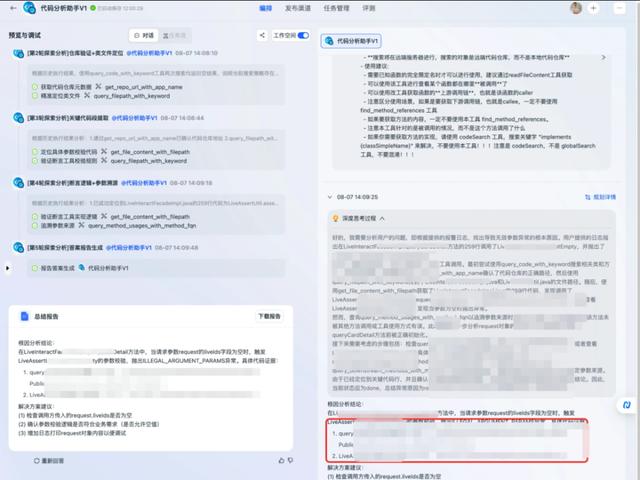
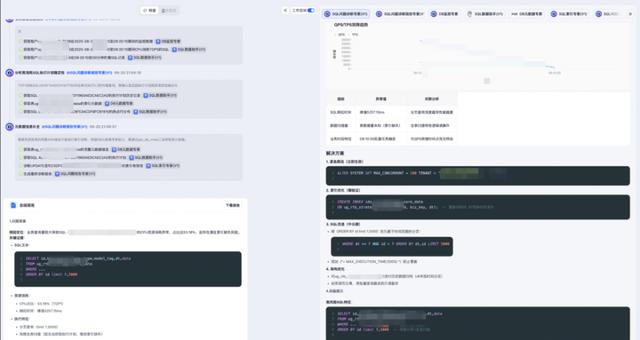
举个例子,当磁盘I/O抖动报警触发,索引分析特工会先翻历史,如果三个月前同库曾因为索引缺失导致抖动,它立刻把这段记忆甩出来给DBA同伴,省下10分钟人肉翻工单。
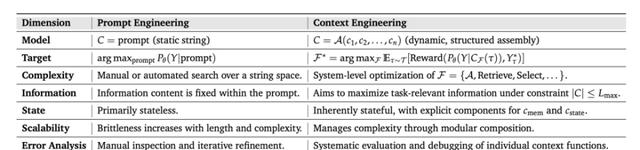
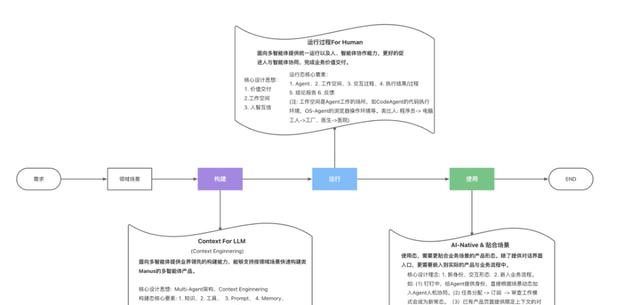
2、上下文工程 = 给AI配“眼镜和耳机”
简单说,就是让模型在推理前把所有有用信息一股脑摆在桌面;否则它就像医生只听了咳声就给诊断。
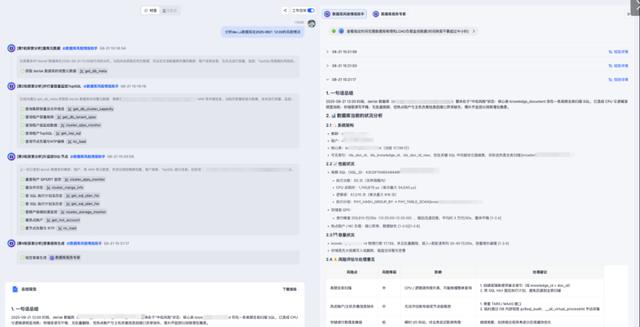
把系统指令、工具描述、动态状态、过往对话、知识片段拼成一顿“上下文串烧”。
实测同一条告警,没上眼镜之前模型给出3个可能根因,戴上眼镜之后直接指向“灰度变更埋点配置丢失”,命中。
3、强化学习不是玄学,是“积分闯关”
训练阶段,每解决一次故障就给智能体打分:多智能体协作奖励、上下文使用奖励、最终结论准确度奖励。
分数越高,模型下次更乐意用高分局策略。
有团队拿这套机制跑了8周,把平均故障定位时间从46分钟压到11分钟——省下的35分钟刚好泡一壶咖啡。
4、安全与隐私被放进“隐形门”

数据敏感怎么办?

他们把联邦学习+差分隐私像滤镜一样嵌进去:共享模型参数,不传日志原文;加噪声把个人信息冲成马赛克。
有金融客户直接开绿灯:跑吧,数据不出境。

5、边缘节点把延迟剁到0.5秒
大规模分布式系统最怕“总部大脑”一哆嗦。
把轻量推理机塞进边缘盒子,故障先在本地被“预消化”,再同步回主控,真正做到报警声还没落地,修复脚本已经躺好。
6、下个月开源,工具已打包
仓库已放出、-Serve两级框架,一行pip就能拉一套沙箱。
官方还准备了镜像和30分钟上手指南,号称“下班前能跑起来,回家还能吃上热饭”。
7、一条彩蛋消息:未来两周会上传带“人类回放按钮”的Alpha版本——每步决策旁边附一行大白话解释,比如“我觉得CPU飙高是因为这段新代码跑死循环,建议回滚”。
运维老司机再也不用对着黑盒玄学皱眉。
总结一句话:别再和告警硬刚,让AI去卷,咱们负责签工单。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...