实现各种注意力机制。
注意力()机制最早在计算机视觉中应用,后来又在 NLP 领域发扬光大,该机制将有限的注意力集中在重点信息上,从而节省资源,快速获得最有效的信息。
2014 年, 发表《 of 》,使注意力机制流行起来;2015 年, 等人在论文《 by to Align and 》中,将注意力机制首次应用在 NLP 领域;2017 年, 机器翻译团队发表的《 is All You Need》中,完全抛弃了 RNN 和 CNN 等网络结构,而仅仅采用注意力机制来进行机器翻译任务,并且取得了很好的效果,注意力机制也因此成了研究热点。
经过几年的发展,领域内产生了众多的注意力机制论文研究,这些工作在 CV、NLP 领域取得了较好的效果。近日,在 上,有研究者介绍了 17 篇关于注意力机制论文的 的代码实现以及使用方法。
项目地址:
项目介绍
项目作者对注意力机制进行了分类,分为三个系列: 系列、MLP 系列、ReP(Re-)系列。其中 系列中包含有大名鼎鼎的《 is All You Need》等 11 篇论文;最近比较热门的 MLP 系列包括谷歌的 MLP-Mixer、gMLP , 的 ,清华的 ;此外,ReP(Re-)系列包括清华等提出的 、 ACNet。
系列的 11 篇 论文 实现方式如下:

MLP(多层感知机)系列中,包含 4 篇论文 实现方式,论文如下:

ReP(Re-)系列中,包含 2 篇论文 实现方式,论文如下:

总结来说,该项目共用 实现了 17 篇注意力机制论文。每篇论文包括题目(可直接链接到论文)、网络架构、代码。示例如下:
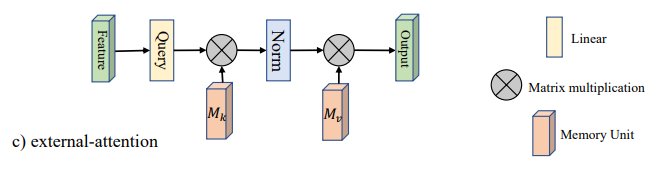
论文:「 Self-: using Two for Tasks」。
网络框架:
代码:
from attention.ExternalAttention *import* ExternalAttentionimport torchinput=torch.randn(50,49,512)ea = ExternalAttention(d_model=512,S=8)output=ea(input)print(output.shape)
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...