

点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!

刚刚,又有一家AI公司开源了一个的LLM模型:DBRX。DBRX 是由 创建的一个开放、通用的大型语言模型(LLM)。在一系列标准的基准测试中,DBRX 为现有的开放大型语言模型设定了新的最高标准。此外,它为开放社区和构建自己的大型语言模型的企业提供了一些以前仅限于封闭模型 API 的能力;根据目前的评测,它超越了 GPT-3.5,并且与 1.0 Pro 竞争。DBRX 特别擅长代码模型,在编程方面超越了像 -70B 这样的专门模型,除此之外,它作为一个通用的大型语言模型也非常强大。目前代码和模型已经发布:
DBRX 是一个基于 的仅解码器的大型语言模型(LLM)。它使用了具有 132B总参数的细粒度混合专家(MoE)架构,其中 激活参数为36B。DBRX 在文本和代码数据的 12T 上进行了预训练。与其他开放的 MoE 模型如 和 Grok-1 相比,DBRX 是细粒度的,意味着它使用了更多数量的较小专家。DBRX 有 16 个专家并选择 4 个,而 和 Grok-1 有 8 个专家并选择 2 个。这提供了 65 倍可能的专家组合,我们发现这提高了模型的质量。DBRX 使用旋转位置编码(RoPE)、门控线性单元(GLU)和分组查询注意力(GQA)。它使用 GPT-4 。DBRX 在 12T 的精心收集的数据上进行了预训练,最大上下文长度为 32k 。
DBRX 在语言理解、编程、数学和逻辑方面轻松超越了开源模型,例如 -70B、 和 Grok-1。实际上,开源基准测试 包含了超过 30 个不同的最先进(SOTA)基准测试,DBRX 在所有这些模型中表现最佳。
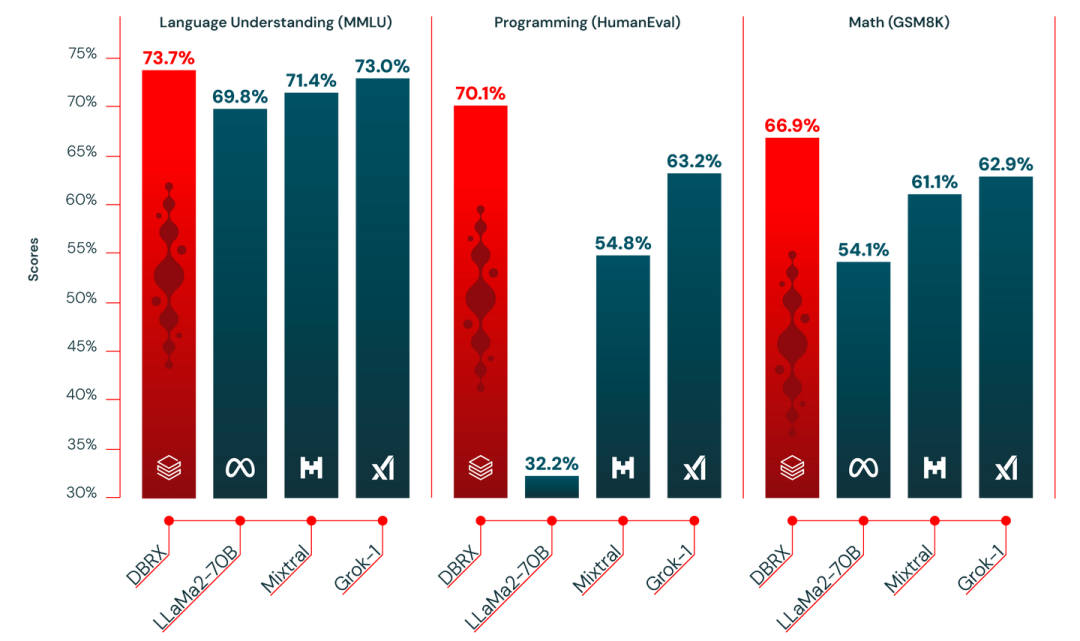
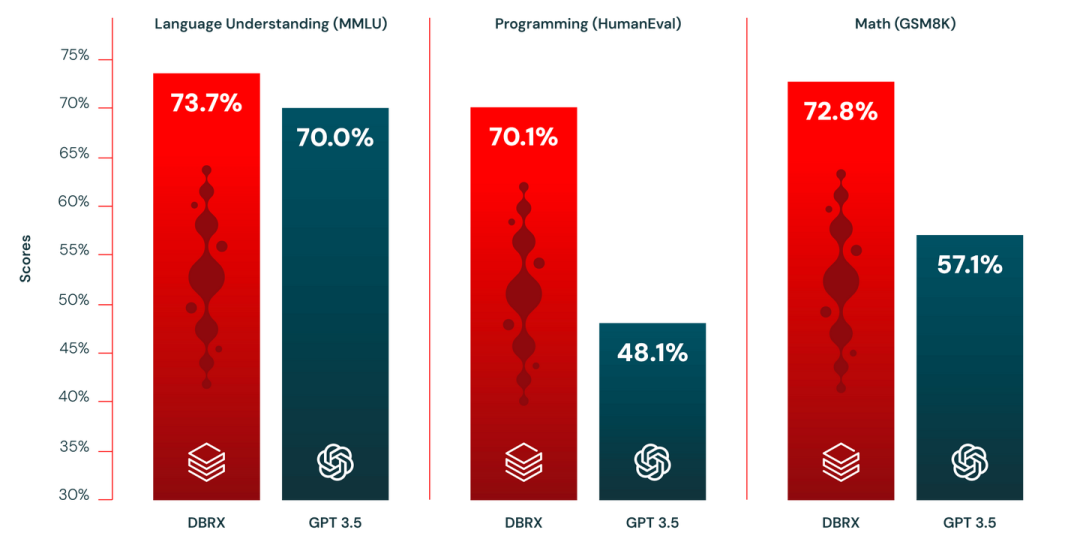
其次,DBRX 在大多数基准测试中超越了 GPT-3.5。
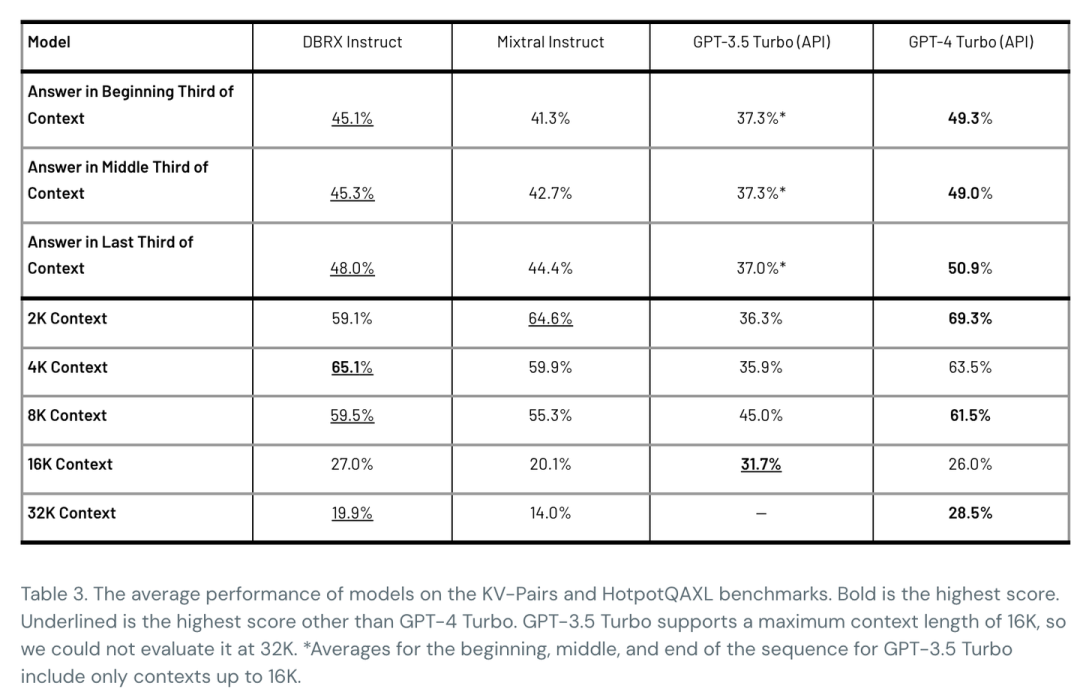
DBRX 最终支持32K 上下文,在不同上下文长度设置上,DBRX 几乎全部超过了GPT-3.5 Turbo。
添加图片注释,不超过 140 字(可选)
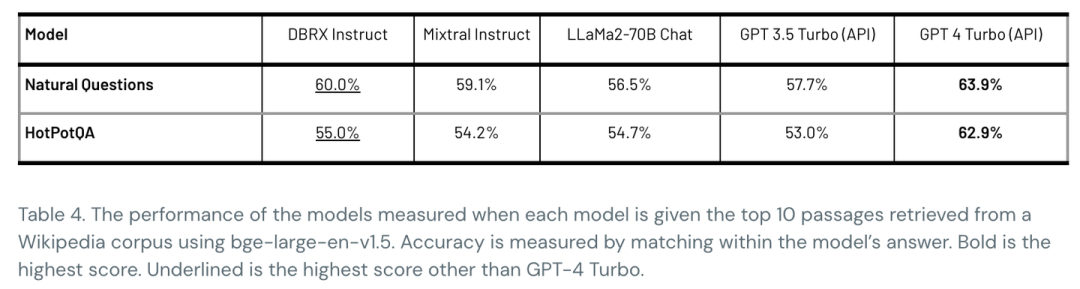
而且DBRX 在RAG上也和一些SOTA模型有很好的竞争力。
添加图片注释,不超过 140 字(可选)
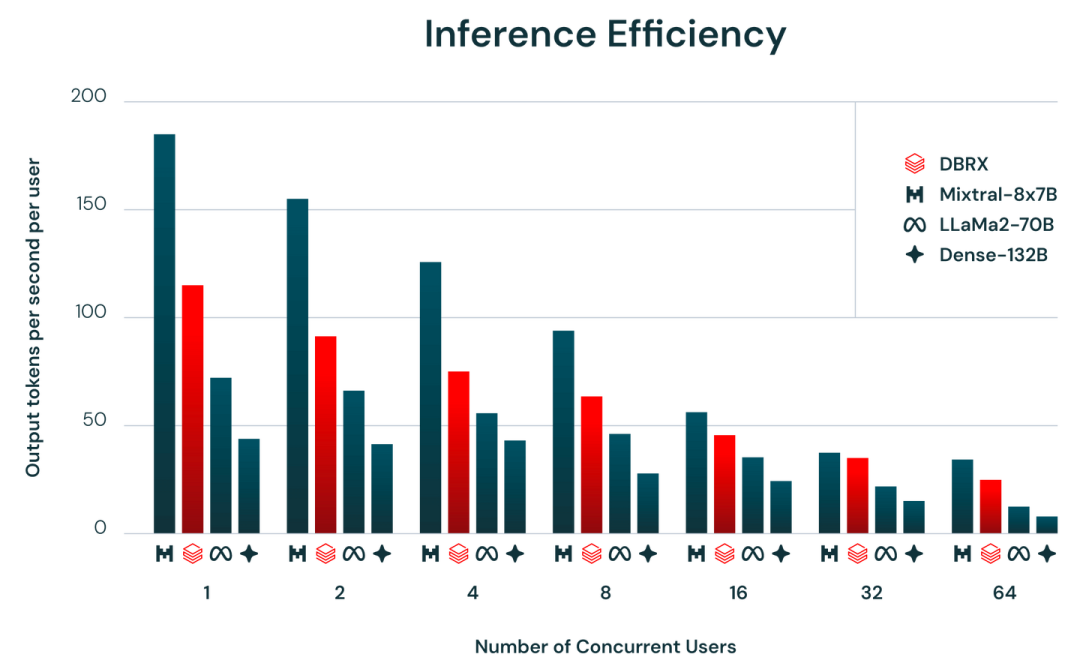
DBRX 通过其细粒度的混合专家(MoE)架构,有很高的训练和推理效率。推理速度比 -70B 快达 2 倍,并且在总体和活跃参数计数方面,DBRX 的大小约为 Grok-1 的 40%。当部署在 AI 模型服务上时,DBRX 能够以每个用户每秒高达 150 个 的速度生成文本。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...