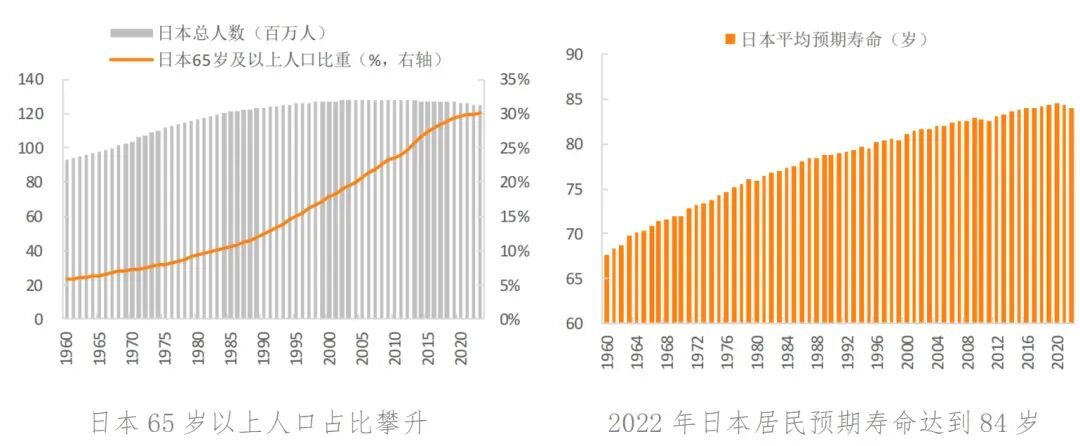
在机器学习(ML)中,可解释性和可理解性是理解和掌握模型如何做出某些决策的关键。
让我们分解这些概念并突出它们的区别:
可解释性:
可解释性指的是人类能够理解机器学习模型的输入特征与输出预测之间的因果关系的程度。
一个可解释的模型使得包括数据科学家和非专家在内的利益相关者能够理解模型决策背后的逻辑。
这种理解建立了信任并有助于验证模型的可靠性。
方法:
线性模型、决策树和较简单的算法通常天生具有较高的可解释性。
它们简单直观的结构使得决策过程易于追踪。
例子:
一个根据特征如平方英尺、卧室数量和位置来预测房价的线性回归模型就是可解释的。
每个特征分配的系数直接显示了它们对预测价格的影响。
可理解性:
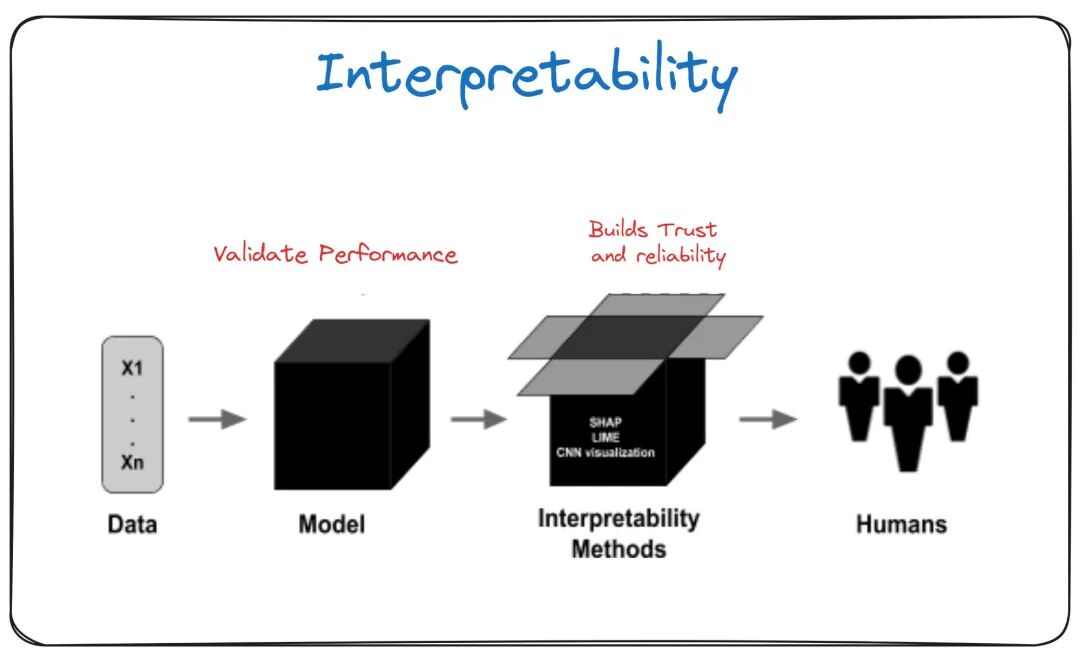
可理解性则专注于以更详细和易于理解的方式提供机器学习模型的内部机制和决策过程的洞见。
虽然可解释性关注于理解整体行为,可理解性则深入到个别预测。
它有助于回答像“为什么在这个特定实例中作出了这个特定的决定?”这样的问题。
方法:
像SHAP( )值、LIME(Local Model- )以及神经网络中的注意力机制等技术增强了可理解性。
例子:
在一个用于图像识别的复杂深度学习模型中,可理解性可能揭示网络中的某些神经元对特定特征如边缘、纹理或颜色的反应,给出模型如何感知和处理图像的详细视图。
总结,可解释性涉及理解模型的整体功能,而可理解性则深入探究个别预测的具体情况。
两者对于确保机器学习模型的透明度、信任和道德使用都至关重要。
你是否在你的模型中使用过可理解性或可解释性技术?
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...