
时间安排
报名时间:即日起至2025年9月27日
项目持续时间:2025年9月29日~10月13日(10月1日~8日休假)
项目介绍
图生文技术在现实中有广泛的应用场景,比如为视障人群提供出行辅助、根据图片生成商品或场景的描述、在临床诊疗中生成诊断和识别手写处方等。本项目将以一个典型的场景“基于电影海报生成电影名称”为例,引导学员掌握基础文生图模型的实现
电影名,尤其是外文电影的中文译名,对观众的观影和传播热情有重要影响。而电影海报常常包含电影中的关键人物与情节线索,如果能够将其转化为简练而生动的文字表达,对于电影的推广无疑是一大助力
本项目以电影海报图像为输入,以和LSTM模型为基础,构建了一个图生文模型来预测电影名。学员将掌握图像和文本数据预处理与建立图生文模型相关的各种操作,包括:将图像规范成输入X,将文本数据规范成统一长度特征向量Y,以此建立图生文模型的训练集;熟悉迁移学习的一系列操作,建立模型实现基于海报图像生成电影名称的任务
项目为期一周,提供数据、案例讲解视频、 编写的代码文档、云GPU计算服务等资源
适用对象:(1) 具备一定的深度学习基础:熟悉和Keras框架,熟悉中图像规范处理、文本特征提取等基本操作的深度学习初学者;(2) 项目期间一周能保证3~4小时学习时间
你的收获
本项目重点在以下环节进行强化训练
图像数据处理方法;中文文本分词、向量化等预处理方法
适配图生文任务的模态转换模型搭建思路
迁移学习的基本原理和实现方法
获得一份能力证明:狗熊会为按要求完成全部TASK的营员提供实习证明;优秀营员有机会获得知名企业的工作机会,简历直推高管
积累更多实战经验和影响力:狗熊会精品案例组、企业合作研究项目组优先招募优秀营员;营员优秀作品经过审核后可发表在狗熊会公众号,扩大营员的知名度和影响力

实习证明样例
任务清单
Task 1:电影海报图像、电影名文本数据预处理,建立图生文模型数据集
Task 2:搭建图生文模型,训练模型并输出电影名
项目说明
项目全程采取线上远程形式进行,项目包含若干个TASK。每个TASK周期都包含如下环节:(1)导师发布任务要求和参考资料;(2)营员自学参考资料,如果有自己无法解决的问题,向老师和助教求助;(3)营员完成任务后,老师反馈评分+评语,对重点难点和多发问题做集中总结
项目依托狗熊会与知名GPU共享平台矩池云共同打造的深度学习平台。上机所需要GPU环境基本配置: GPU,每秒浮点运算次数13.13 ,显卡内存 11 GB,GPU带宽 616 GB/s。项目费用已包含在该环境下完成任务所需的基本机时(不超过100小时);如果机时不够,营员可通过狗熊会以优惠价格继续购买;未消耗完的机时,概不退款
项目结束后180天内,营员可继续使用项目相关所有资料进行复习和强化训练,并可继续通过狗熊会或矩池云以折扣价购买GPU机时
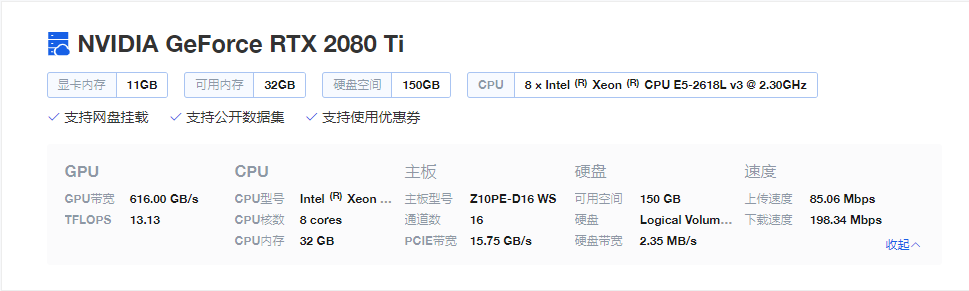
GPU配置单
费用说明
费用:680元/人
售后服务-1天无理由退款:
接受高校客户集体报名。关于项目与报名如有问题,请咨询。
数据分析从入门到精通,狗熊学习卡助您一臂之力!69元/年,狗熊会所有视频课程无限看,代码轻松学。欢迎小伙伴们扫码购入~

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...