
研究团队预期这一成果可以被扩展到更高维的、更接近现实应用的机器人问题中,帮助自动化设计一些奖励函数用于训练机器人完成复杂的任务。而用于设计奖励函数的数据集可以不再囿于采集自同类机器人成功完成任务的数据,而是可以采集任何具有相似能力的智能体的视频数据,甚至采集人类示范的视频数据。
在训练智能体完成一些缺乏明确任务进度评价的任务时,人们往往需要增加很多额外的监督信号来帮助训练。比如,使用强化学习算法训练控制机械手解决一个魔方时,最直观的任务完成信号只有是否能在指定时间内完成魔方这一非常宏观的评价指标,任务完成过程中没有任何具体定义步骤对错的简单标准。
而直接使用“任务完成与否”这一单一指标会导致强化学习算法几乎无法得到有效的训练数据,因为在随机探索过程中算法偶然碰撞出正确控制机械手解决魔方的概率几乎为零。
也正因此,在 Open AI 早期训练机械手解决魔方的论文中,他们添加了很多额外的奖励信号用于监督诸如机械手的手指动作是否合理,以及魔方当前状态是否符合算法规划的解决方案等。
另一个例子是人们在玩电子游戏的时候如果中途没有任何任务指引或者分数反馈,只有在游戏结束才能知道是否胜利的话,人们就会觉得这个游戏很难通关,或者需要尝试很久才能猜出正确的胜利条件。
所以,在训练智能体过程中,研究人员往往需要针对特定任务增加很多额外的奖惩信号作为过程监督帮助智能体学习。这样一种增加额外奖励信号并且不影响智能体最终能学会的最优策略的算法叫 PBRS( Based ),由华人学者吴恩达于 1999 年提出。
但是,这样就会导致每碰到一个新的任务,都需要花费大量时间和人力来设计并调整奖励信号。这样的解决方案在现代社会日益增长的智能体需求下完全不具有可持续性。
所以,本次研究团队考虑的是能否直接从现有数据中学习到一个合理的额外奖励信号呢?直观来讲是可以的,即使用蒙特卡洛法估算价值函数。而每两个状态之间的价值差就可以作为一个额外的奖励信号(智能体从低价值状态转移到高价值状态就会得到一个正向的奖励,反之则是惩罚)。
但是,如果数据集不是由一个性能很好的智能体产生的,又或者数据集里包含一些没有被观测到的混杂偏差呢?这时直接用蒙特卡洛法估计出来的价值函数就不再是无偏的,并且可能会和最优价值函数相去甚远。
于是,在本次论文里研究团队探索了如何使用一些因果推断的工具来自动地从多个可能有混杂偏差的数据集里学习到合理的奖励函数,并从理论上证明解释了为何此类奖励函数能够显著提高特定智能体训练的效率,大量实验结果也证明了本次发现。
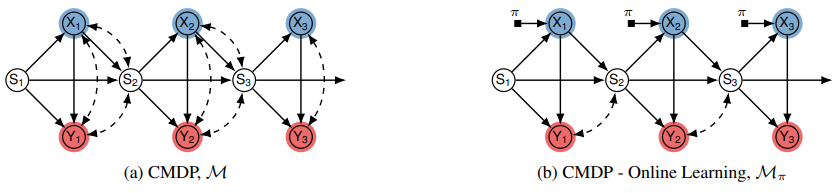
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...