
卷友们除夕快乐!另外帮小伙伴推广一下 首届AI春晚,马上6点钟开播, 感受AI技术的进步~ 明天初一休息,已经定时了一周AI文章。

https://arxiv.org/pdf/2402.05123.pdf
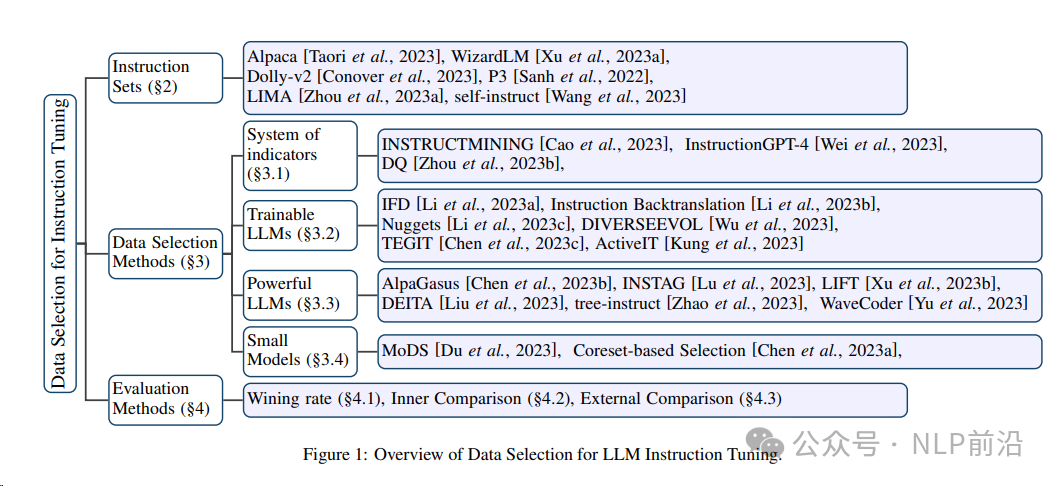
这篇文章是关于大型语言模型(LLM)指令调整( )的数据选择方法的综述。文章首先介绍了LLM训练过程中的两个基本步骤:在大规模语料库上进行预训练()和在指令数据集上进行微调(Fine-)。在微调阶段,数据集的质量比数量更为重要。因此,文章重点探讨了如何从指令数据集中选择高质量的子集,以减少训练成本并提高LLM遵循指令的能力。
文章提出了一个新的数据选择方法的分类体系,并详细介绍了近期的进展。数据选择方法主要分为四类:
基于指标体系的方法:这些方法使用一组指标(如指令长度、困惑度、奖励分数等)来评估数据点的质量。通过计算每个数据实例的分数,然后根据分数选择数据子集。
基于可训练LLM的方法:这类方法利用可训练的大型语言模型(如LLaMa)来开发数据选择过程中的计算公式。模型会处理并为每条指令微调数据分配分数。
基于强大的LLM的方法:这些方法使用像这样的强大LLM作为数据选择器,通过设计提示模板来评估指令数据的质量。
基于小型模型的方法:这些方法通常涉及使用外部小型模型作为评分器,或者将指令转换为嵌入向量,然后进行进一步处理。
文章还详细介绍了评估数据选择方法的有效性的方法,包括胜率( Rate)、内部比较(Inner )和外部比较( )。胜率是通过比较LLM在子集上微调后的性能与基础LLM的性能来计算的。内部比较是将LLM在子集上的性能与在完整训练集或相同规模的随机子集上的性能进行比较。外部比较则是将LLM在子集上的性能与外部LLM在不同测试基准上的性能进行比较。
最后,文章强调了数据选择在LLM指令调整中的重要性,并提出了当前研究中的挑战和未来的研究方向,如缺乏统一的评估标准、处理大量数据的效率问题以及对特定语言和领域的数据选择方法的研究。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...