
选自
机器之心编译
参与:吴攀
论文:事件驱动的随机反向传播:能实现神经形态深度学习(Event- : Deep )

神经形态计算( )领域内一个一直以来持续存在的挑战是设计兼容大脑的时间和空间约束( and )的通用的且计算高效的推理和学习模型。梯度下降反向传播规则( rule)是一种强大的算法,现在已经在深度学习领域无处不在,但这种算法依赖于使用高精度记忆存储的整个网络那么宽的信息的即时可用性。
但是,近来的研究成果表明:准确的反向传播的权重对学习深度表征而言并不是必需的。随机反向传播( )使用了随机的权重来替换反馈的权重并鼓励()该网络调整其前馈权重,从而学习该(随机)反馈权重的伪逆(-)。在这里,我们提出了事件驱动的随机反向传播(event- ,简称 eRBP)规则,其使用了一种误差调制的突触可塑性(error- ),可用于在神经形态计算硬件中学习深度表征。对于使用了 two- leaky & fire 和膜电压调制的、尖峰驱动的可塑性规则(- , spike- rule)的神经形态硬件,我们提出的这个规则非常适合于其中的实现。
我们的结果表明:使用 eRBP,无需使用反向传播的梯度就能快速学习到深度表征,并能实现可与在 GPU 上的人工神经网络模拟相媲美的分类准确度,同时也对学习过程中的神经和突触状态量化( and state )是稳健的。
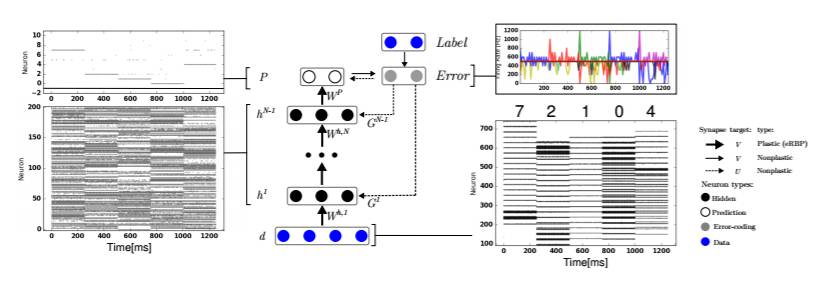
图 1:用于事件驱动的随机反向传播(eRBP)的网络架构和训练过程中的尖峰活动示例。该网络包含用于预测的前馈层和用于有标签(目标)L 的监督训练的反馈层。实线箭头表示突触连接,虚线箭头表示突触可塑性调制( )。在这个示例中,数字 7,2,1,0,4 被以序列的形式提供给该网络。这些数字像素值被使用尖峰响应模型(Spike Model)转换成了尖峰串(spike )。该网络中的所有其它神经元都实现了 two- leaky I&F 。这个误差是标签(L)和预测(P)之间的差,其中偏移设置为 500 Hz。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...