
1. 在线和离线特征
如果在训练和推理系统中特征工程代码不相同,则存在代码不一致的风险,因此,预测可能不可靠,因为特征可能不相同。一种解决方案是让特征工程作业将特征据写入在线和离线数据库。训练和推理应用程序在做出预测时都需要读取特征-在线应用可能需要低延迟(实时)访问该特征数据,另一种解决方案是使用共享特征工程库(在线应用程序和训练应用程序使用相同的共享库)。
2. 时间旅行
“考虑到过去发生的事件,事件发生期间特征价值是什么?“
通常数据库不支持时间旅行,即通常无法在某个时间点查询某个列的值。当然可以通过确保定义特征数据的都包含 / event-time列来解决此问题,最近的数据湖通过存储所有更新以支持对旧特征值查询,从而增加了对时间旅行查询的支持。一些支持时间旅行功能的数据平台:
3. 特征工程
添加了特定领域语言(DSL)以支持原始数据源(数据库,数据湖)的工程特征。使用通用框架(如 Spark / ,,Flink和 Beam)也是一个不错的选择。
4. 物化训练/测试数据

模型的训练数据既可以直接从特征存储传输到模型中,也可以物化到存储系统(例如S3,HDFS或本地文件系统)中。如果将多个框架用于ML – ,,-Learn,则建议将训练/测试数据物化为框架的本机文件格式(为.,为.npy)。
ML框架的常见文件格式:
5. 在线特征存储
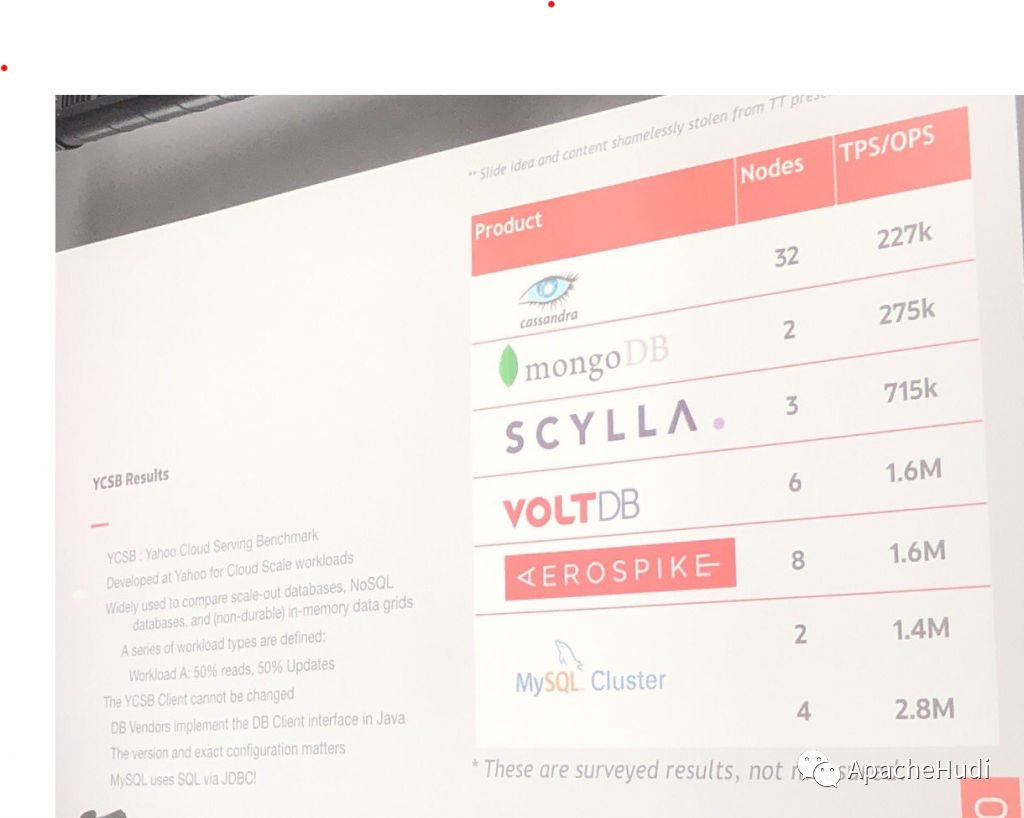
模型可能具有数百个特征,但是在线应用程序可能只是从用户交互(,,,等)中接收了其中的一些特征。在线应用程序使用在线特征存储来查找缺失的特征并构建特征向量,该特征向量被发送到在线模型以进行预测。在线模型通常通过网络提供服务,因为它将模型的生命周期与应用程序的生命周期不相同。在线特征存储的延迟、吞吐量、安全性和高可用性对于其在企业中的成功至关重要。下面显示了现有特征存储中使用k-v数据库和内存数据库的吞吐量。
6. 特征存储对比
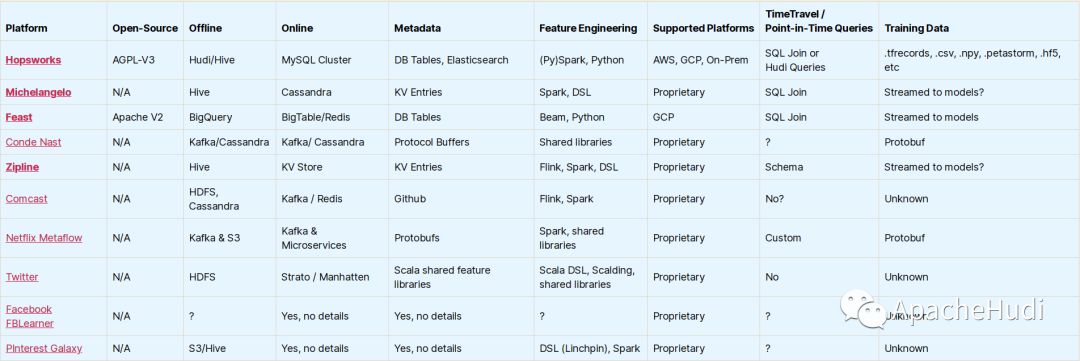
7. 特征存储架构


© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...