
国庆闲暇之余,买了一本书来看,里面提到了怎么用的强化学习方法来优化资产配置。这里给大家分享一下。
1、什么是?
这里我用自己的理解和语言,简单给大家解释一下原理。如果有理解不到位之处,还请谅解。
记得第一次接触强化学习的时候是2020年了,那会学习这个也是为了能用在资产配置上。但是,那会觉得方法太复杂了。
不仅是,包括其他强化学习方法如actor-,都存在一个问题:就是这个环境或者游戏,最好能够不停地重复进行,这样才能获得足够的样本来训练网络,而且能够使用更新后的网络来重复游戏,并不停训练网络。
正是这个原因,才很久没有进一步深入研究这个才资产配置上的使用。因为金融市场很多数据都是有限的,而且你没法完全重复市场,历史也不一定代表未来。
所谓,可以理解为构建了一个表格,这个表格,对应了不同的市场环境(State),一种state环境对应着不同概率的操作,应该采用哪种操作(),则选择最大概率的操作方式。
而这个怎么获得呢?就是使用不同环境、不同操作下的收益来更新这个表格。所以最好有足够的数据,才能让这个变得更可靠。
2、的由来
大放异彩,是2015年提出了利用神经网络实现的算法用于在Arari游戏环境中的49个游戏上训练,都取得了人类水平或者超越人类水平的表现。
简单来说,算法通过以下公式来更新网络:
就是使用深度神经网络Q网络来参数化Q函数,并利用梯度下降来更新网络。
也正是因为神经网络的训练都需要足够多的数据才更为可靠,所以一直以为在资产配置领域,这个是很难使用的,直至最近看到书上再次介绍这种方法。
但是,书上介绍的Q网络,实际上是简单的一种网络,甚至可以理解为最简单的规则性网络,并没有使用深度学习。那么,这就有可能让这种方式在实操中具有可行性。
而且,使用的范畴还能更广,还可以用于多因子模型。多因子的模型,和资产配置中权重的调整也是具有相通之处的。比如,因子往往在不同的市场环境,有效性是不同的,所以我们可以根据市场环境的不同,选择不同的最优操作,这就是的优势之处了。
3、怎么实现?
要实现,其实很简单,直接交给AI就可以了。
以下是AI实现的效果,给大家展示一下(数据为月度数据,长度132,模拟生成的数据):
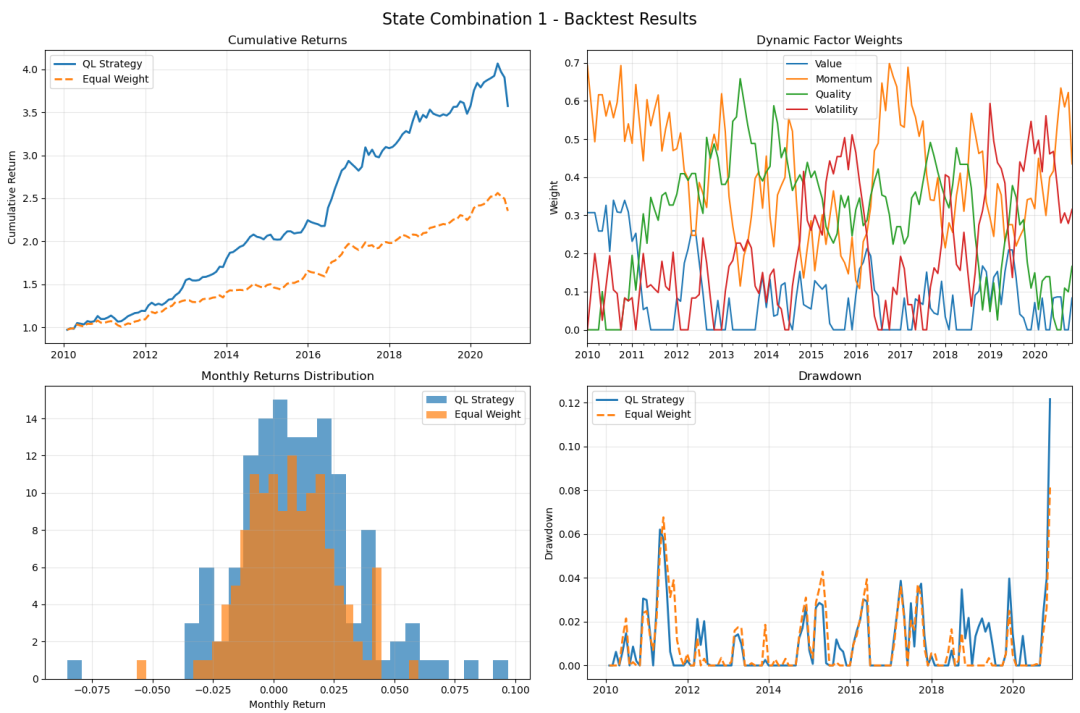
整个网络的框架架构太长了,这里给大家简单介绍下:
(1)构建一个类。在这个类下面,我们可以定义市场状态有100种,操作的组合有81种,那么就是一个100*81的表格,每一行代表某一种市场状态下采用各个操作的状态,每一个操作,我们对应着一种资产调整的一种方式。
(2)网络建立好以后,就可以更新这个了。比如,从历史上的第一种状态开始遍历,每一种状态根据q网络的规则选择的某一行(不同概率的具体操作),然后再选择这一行概率最大值对应的操作,在计算这种操作下的激励(),这个激励也可以自己来定义,比如正超额收益+1分,负超额收益-1分。
(3)根据奖励情况,以及上述公式,更新的概率值。
因为市场不可能重复,或者数据相对有限,那么上述更新的次数就会优先。但从上述市场模拟数据来看,还是有一定改善效果的,可以提高夏普值。
源代码,我们上传至合集 ,有需要的可以去下载,大家也可以让AI自动生成调试。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...