
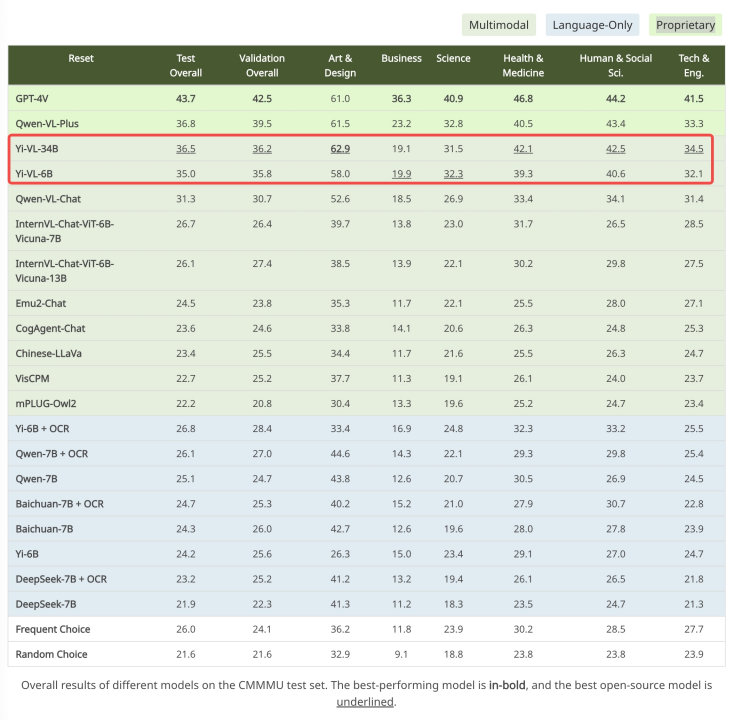
在针对中文场景打造的 CMMMU 数据集上,Yi-VL 模型展现了「更懂中国人」的独特优势。CMMMU 包含了约 12000 道源自大学考试、测验和教科书的中文多模态问题。其中,GPT-4V 在该测试集上的准确率为 43.7%, Yi-VL-34B 以 36.5% 的准确率紧随其后,在现有的开源多模态模型中处于领先位置。

来源:
那么,Yi-VL 模型在图文对话等多元场景中的表现如何?
我们先看两个示例:


可以看到,基于 Yi 语言模型的强大文本理解能力,只需对图片进行对齐,就可以得到不错的多模态视觉语言模型 —— 这也是 Yi-VL 模型的核心亮点之一。
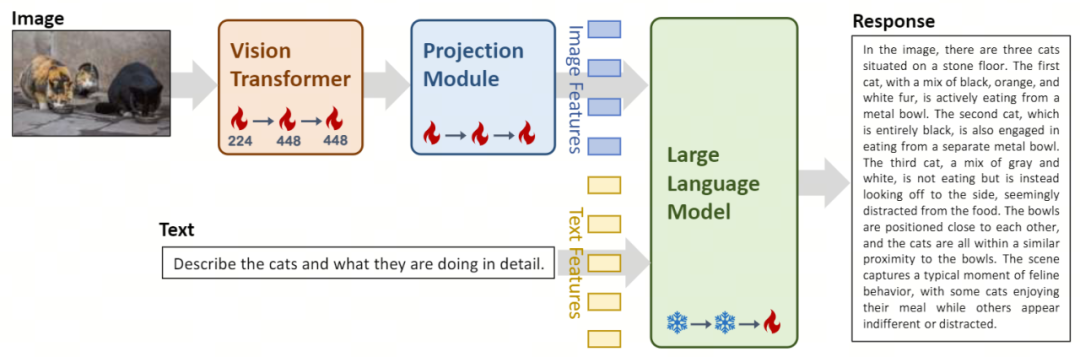
Yi-VL 模型架构设计和训练方法流程一览。
在架构设计上,Yi-VL 模型基于开源 LLaVA 架构,包含三个主要模块:
在训练方法上,Yi-VL 模型的训练过程分为三个精心设计的阶段,旨在全面提升模型的视觉和语言处理能力。
零一万物技术团队同时也验证了可以基于 Yi 语言模型强大的语言理解和生成能力,用其他多模态训练方法比如 BLIP、、EVA 等快速训练出能够进行高效图像理解和流畅图文对话的多模态图文模型。Yi 系列模型可以作为多模态模型的基座语言模型,给开源社区提供一个新的选项。
目前,Yi-VL 模型已在 Face、 等平台上向公众开放,用户可通过以下链接亲身体验这款模型在图文对话等多元场景中的优异表现。欢迎探索 Yi-VL 多模态语言模型的强大功能,体验前沿的 AI 技术成果。

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...