
“喂,它明明读了整本说明书,却连开关都找不到。

把大模型比作一个记忆力惊人却常常走神的朋友,这句话就成立。
上下文窗口飙到百万token,听起来像给这位朋友塞了整座图书馆,可书一多,反而找不到重点——这就是圈子里悄悄流传的“”。
先说人话:上下文不是越长越好,而是越“干净”越好。
就像搬家,把全部家当一股脑塞进卡车,到了新家翻箱倒柜找牙刷,效率低到崩溃。
AI也怕这种“信息搬家”。
那怎么办?

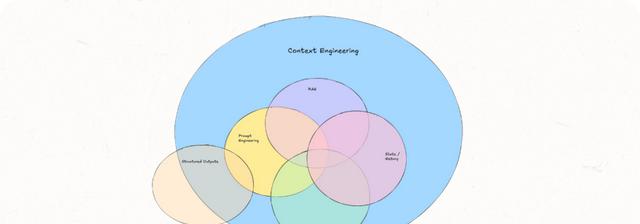
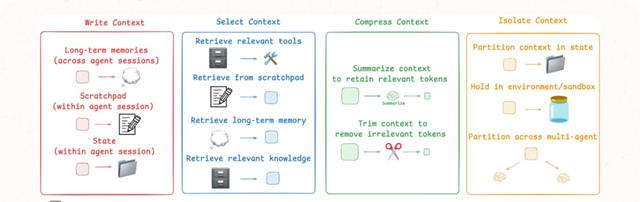
上下文工程来了,它不是玄学,是四步打包术:
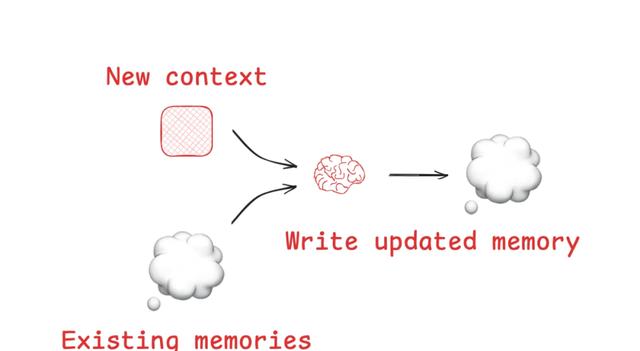
1. 写入——把关键推理、中间结果存成便签,别指望模型自己记得。
2. 选择——别让无关八卦混进来,先筛后放,宁可少,不可乱。
3. 压缩——长话短说,摘要+剪枝,省token就是省算力。
4. 隔离——把不同任务放进不同“抽屉”,客服别跟财务抢台词。
听起来像收纳整理?
没错,但收纳的是“注意力”。
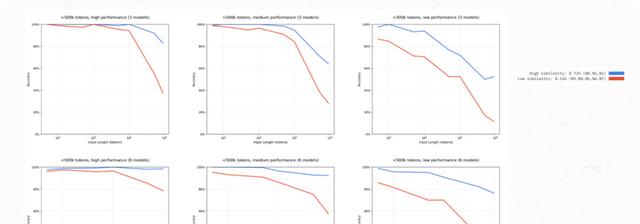
最新实验里,把一份50页合同直接扔给,它能在第37页把“违约金条款”抄错;先用上下文工程筛成3页重点,错误率直接降到1%。
数字不骗人。
更狠的是,这套打法已经杀进多模态。
一段客服语音+截图+订单文本,传统RAG只能各查各的,现在用上下文工程把它们压成一条“用户此刻最在意什么”的向量,再交给模型,回复不再鸡同鸭讲。
Meta刚放出的demo里,AI能边看用户晒的破洞鞋照片,边调出退货政策,还能识别“鞋底开胶”属于质保范围,全程不到两秒。
工具层面也卷疯了。
像乐高,拖拽就能搭一条“写入-选择-压缩-隔离”流水线;干脆给每个用户建了一个“记忆保险箱”,聊天记录、偏好、历史订单自动归档,下次对话直接续上,像老朋友记得你上次咖啡要半糖。
当然,麻烦也跟着升级。
上下文里塞了太多用户隐私,一旦泄露就是社死现场。
现在圈子里流行“差分隐私+联邦学习”套餐:数据留在本地,模型只带走“模糊影子”,既学到了知识,又摸不到真人。
某头部券商已经这么干,客服机器人能记住客户风险等级,却永远不知道客户真名,合规部终于睡了个好觉。
最接地气的落地在电商。
某家日单量千万的平台,把上下文工程塞进客服Agent,退货、换货、催发货、比价、推荐优惠券,一条对话全搞定。
实测结果:平均对话轮次从7轮降到3轮,人工介入率下降42%,客服团队从“救火队”变成“质检组”。
一位老客服私下吐槽:“以前每天回‘亲稍等’到手指抽筋,现在只处理AI搞不定的刺头,工资还涨了。
所以别再迷信“窗口越长越聪明”。
真正让AI靠谱的是“上下文工程”——把图书馆变成目录清晰的工具箱。
下次听到“百万token”宣传,先问一句:你们家 Rot治了吗?
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...