
近段时间,即梦AI动作不断,更新了视频生成的智能多帧功能、图像4.0模型发布、视频生成“主体参考”功能,而数字人 1.5也上线了。
这可不是普通的AI模型,而是能让虚拟角色“活”起来的革命性工具!
比起之前的数字人模型, 1.5数字人不再呆坐罚站,而是能走位、演戏、调镜头,甚至“随地大小演”。
最近,我实测了即梦团队的这个 1.5数字人新模型,结果真的太了!下面大家就跟着我一探究竟。
一、语义理解:听懂人话,自动演戏
传统数字人只会对口型,但 1.5能解析音频中的情绪和语义。
比如,我设定一位母亲在衣柜帮孩子找校服的场景,然后给的动作提示是“她拿到了小宝的红色校服”。
图片:

上传音频“小宝的红色白条边校服外套呢?昨天明明…哎,在这里,太好了!”
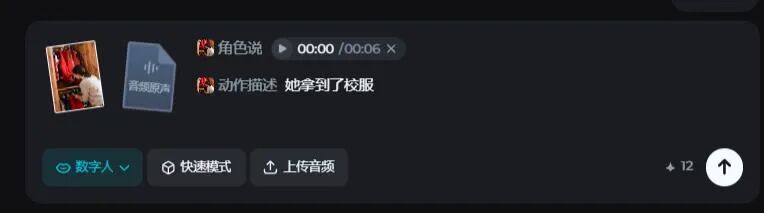
大家可以看到,模型不仅自动生成了拿出红色校服的这个我规定的动作,还配上这位母亲说话时,针对语意的不同表情和动作。
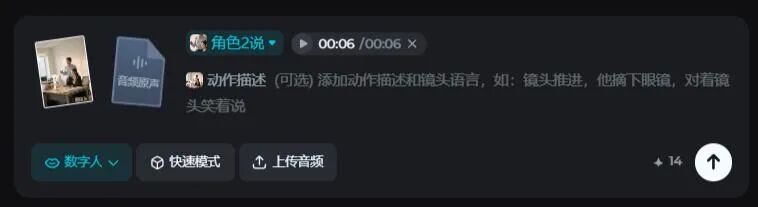
更狠的是,我连动作提示都没给,只上传了一段音频,选择说话角色,模型就可以判断出“男人对女人说话”的这个互动场景,完美还原对话动作!

二、动作调度:复杂走位,镜头随心
1.5不只对嘴型,还能处理时序动作和镜头运动。
比如下面这幅图片:

在数字人模型中,我设置男人的动作:“镜头前推,男人仰望天空,然后摘下眼镜,低头叹气”:
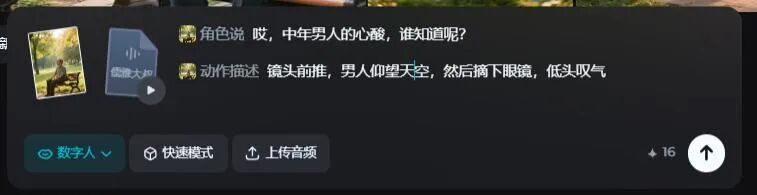
不仅如此, 1.5还可以随着语境,生成其他人物的动作和表情,以及主角走动时,显现出画面中没有的人物及物体。
比如,让下图中的主角快步走进会议室对着会议室的众人说:“抱歉啊,我来晚了。 今天的会议内容是,我看看啊……”。

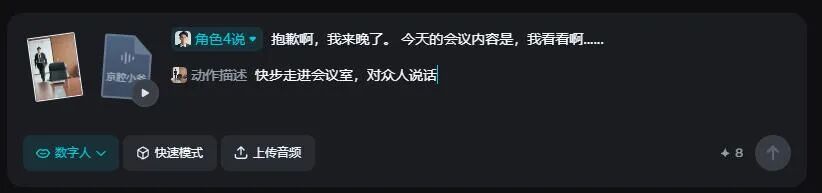
除了原本会议室的人物会跟着主角说话做出相应的动作外,模型竟然还会随着镜头走动补充会议室开会的人物,这补充场景的能力,绝了!
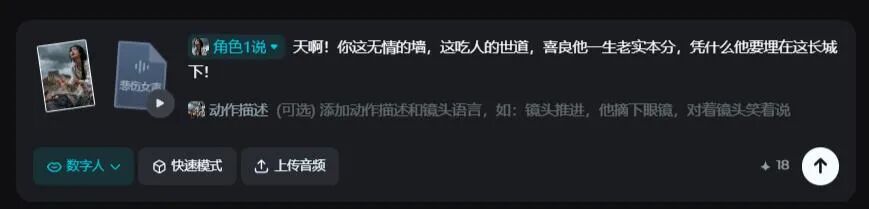
三、情绪演绎:哭戏真香,愤怒更带感
数字人情绪灵不灵?看哭戏!
1.5根据音频起伏调整表演:

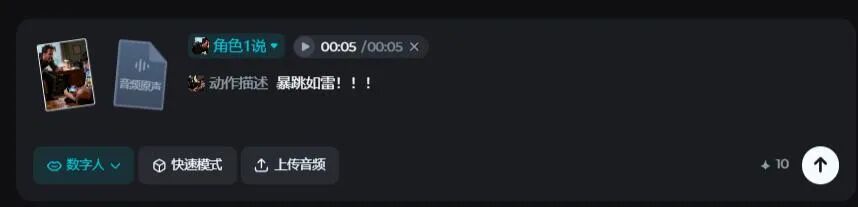
愤怒测试更惊艳,只给“暴跳如雷”提示,模型就输出炸裂效果。

看这表情,绝了。
四、群体协同:多人飙戏,自觉加戏
1.5最大亮点是演群戏!
在多人场景中,模型可以自动识别角色关系,这样我们就可以选择把哪句话分别给哪个角色。
比如:

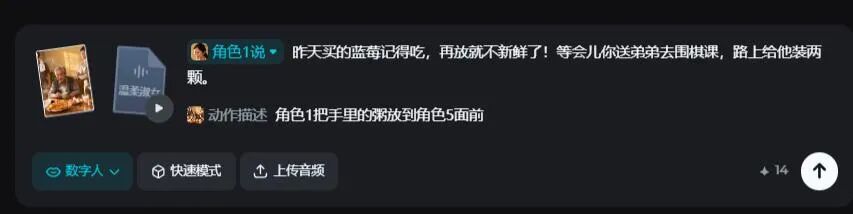
模型会合理的分配所有人的动作表情,因为妈妈在讲话,所以所有人都会抬头(转头)看妈妈。
五、未来玩法:导演的春天来了
如果说前代数字人是布景演员, 1.5就是“可执导的数字演员”。它理解情绪、互动场景、配合镜头,甚至自觉加戏!
我已经脑洞大开:一人拍多角剧?整段MV?第一人称视角剧?模型在即梦Web端已上线了,大家都可以去体验!
1.5不只是技术升级,更是数字人赛道的革命。
它让虚拟角色从“工具”变“伙伴”,导演梦不再遥远。大家觉得呢?欢迎在评论区留下你宝贵的意见!
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...