
随着-R1及其蒸馏模型的发布,许多机器学习工程师都在思考:蒸馏和微调之间有什么区别?为什么在大型语言模型兴起之前非常流行的迁移学习,现在似乎被遗忘了吗?
在本文中,我们将深入探讨它们的差异,并确定哪种方法最适合哪种情况。
注意:虽然本文重点关注大型语言模型,但这些概念也适用于其他AI模型。
1. 微调
虽然这种方法在大型语言模型时代之前就已经被使用,但它在出现之后获得了巨大的普及。如果你知道GPT代表什么——“生成式预训练变换器”( Pre- ),就很容易理解这种崛起的原因。“预训练”部分表明模型已经接受过训练,但可以针对特定目标进行进一步训练。这就是微调的作用所在。
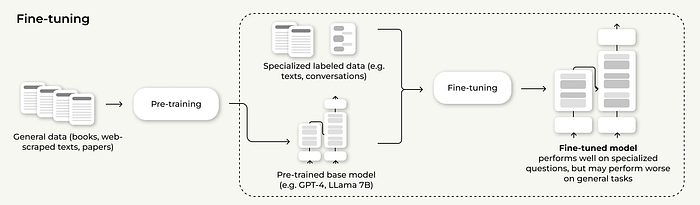
简单来说,微调是一个过程,我们采用一个预训练模型(它已经从一个巨大的数据集中学习了一般模式),然后在较小的、特定任务的数据集上对其进行进一步训练。这有助于模型在专门的任务或领域(如医疗建议或法律文本)上表现更好。
优势缺点示例2. 蒸馏
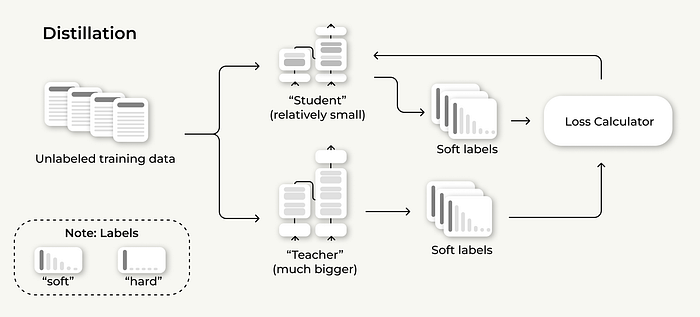
蒸馏,或知识蒸馏,是使用较大、更复杂的模型(“教师”)训练较小、更高效的模型(“学生”)的过程。目标是利用教师模型的知识创建一个运行更快、使用更少内存的学生模型。
蒸馏的一个关键方面是使用软标签而不是标准的硬标签。有什么区别呢?
通常,大型语言模型首先为每个可能的单词生成概率。之后,选择概率最高的单词。例如,如果你问一个大型语言模型:
谁是现任美国总统?
概率分布可能如下所示:
在“标准”训练中,使用硬标签——意味着正确答案(例如,“特朗普”)被设置为100%概率,而所有其他单词被分配0%概率。然而,在知识蒸馏中,我们使用来自教师模型的软标签,允许学生模型从完整的概率分布中学习。这有助于学生模型学习其教师模型的“思维方式”。
优势缺点示例
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...