

在深度学习中,正则化()就像给模型“戴上紧箍咒”,防止它“过度自信”(过拟合)。它的核心作用是让模型在训练时既要学好,又别学得太死板,从而提升在未知数据上的表现(泛化能力)。下面用通俗的方式展开讲解:
1. 为什么要正则化?
过拟合问题:
假设你背数学题答案,把题目和答案的标点符号都背下来了(过度记忆训练数据),但考试换了个问法你就不会了。这就是模型“过拟合”——在训练集上表现极好,但在新数据上表现糟糕。
正则化的作用:
通过给模型增加一些“约束”或“惩罚”,让它学得更泛化,而不是死记硬背训练数据。
2. 常见的正则化方法
(1) L1/L2 正则化(权重衰减)
原理:
在损失函数中额外添加一项,惩罚模型的权重(参数)值。
(鼓励权重稀疏化,适合特征选择)
(让权重整体变小,更平滑)
λ():控制惩罚力度的超参数。
比喻:
老师批改作文时,不仅看内容好坏(原始损失函数),还会惩罚你用生僻词(L1)或啰嗦的长句(L2),逼你写得简洁通用。
(2)
原理:
训练时随机“关闭”一部分神经元(比如50%),迫使网络不依赖任何单一神经元,而是分散学习特征。
测试时:所有神经元激活,但权重按比例缩放。
比喻:
像学生轮流换座位考试,防止他们只抄同桌的答案(不依赖局部特征)。
(3) 数据增强(Data )
原理:
对训练数据做随机变换(如旋转、裁剪、加噪声),人工增加数据多样性。
效果:相当于告诉模型:“记住物体的本质,别纠结图片角度或亮度”。
比喻:
让你用歪着头的照片、黑白照片、模糊照片都认出一只猫,而不是只记住某张特定照片。

(4) 早停(Early )
原理:
监控验证集表现,当性能不再提升时提前终止训练,防止模型“练过头”。
比喻:
考试前模拟考成绩不再提高,就停止复习,避免钻牛角尖。
(5) Batch (间接正则化)
原理:
对每层输入做标准化(减均值、除标准差),减少内部协变量偏移,同时带来轻微噪声,类似的效果。
3. 正则化为什么有效?
数学角度:
通过惩罚大权重,限制模型复杂度(奥卡姆剃刀原理:简单模型更可能泛化)。
概率角度:
相当于给模型参数加先验分布(L2对应高斯先验,L1对应拉普拉斯先验)。
实践角度:
让模型对输入噪声和权重变化更鲁棒。
4. 如何选择正则化方法?
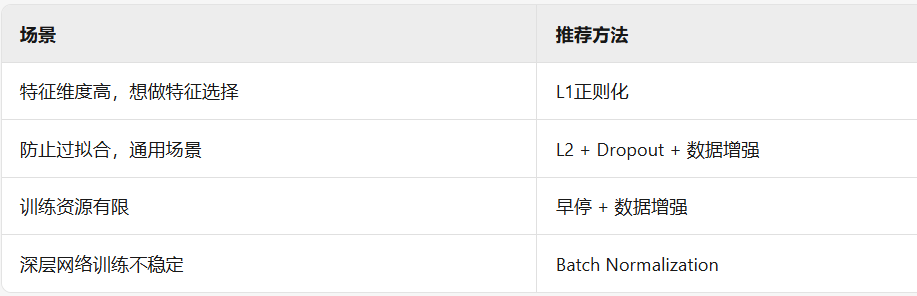
5. 注意事项
正则化不是免费的:
L1/L2可能让训练更慢,需要更多迭代次数。
超参数调优:
λ(正则化强度)、比例等需要实验调整。
别过度正则化:
可能导致模型“学不动”(欠拟合)。
一句话总结:
正则化是深度学习的“防沉迷系统”,让模型在训练时保持克制,最终在真实世界中表现更稳健。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...