
在人工智能的发展历程中, 架构的出现具有里程碑意义。2017 年谷歌团队提出这一模型后,迅速改变了自然语言处理乃至整个 AI 领域的技术格局。
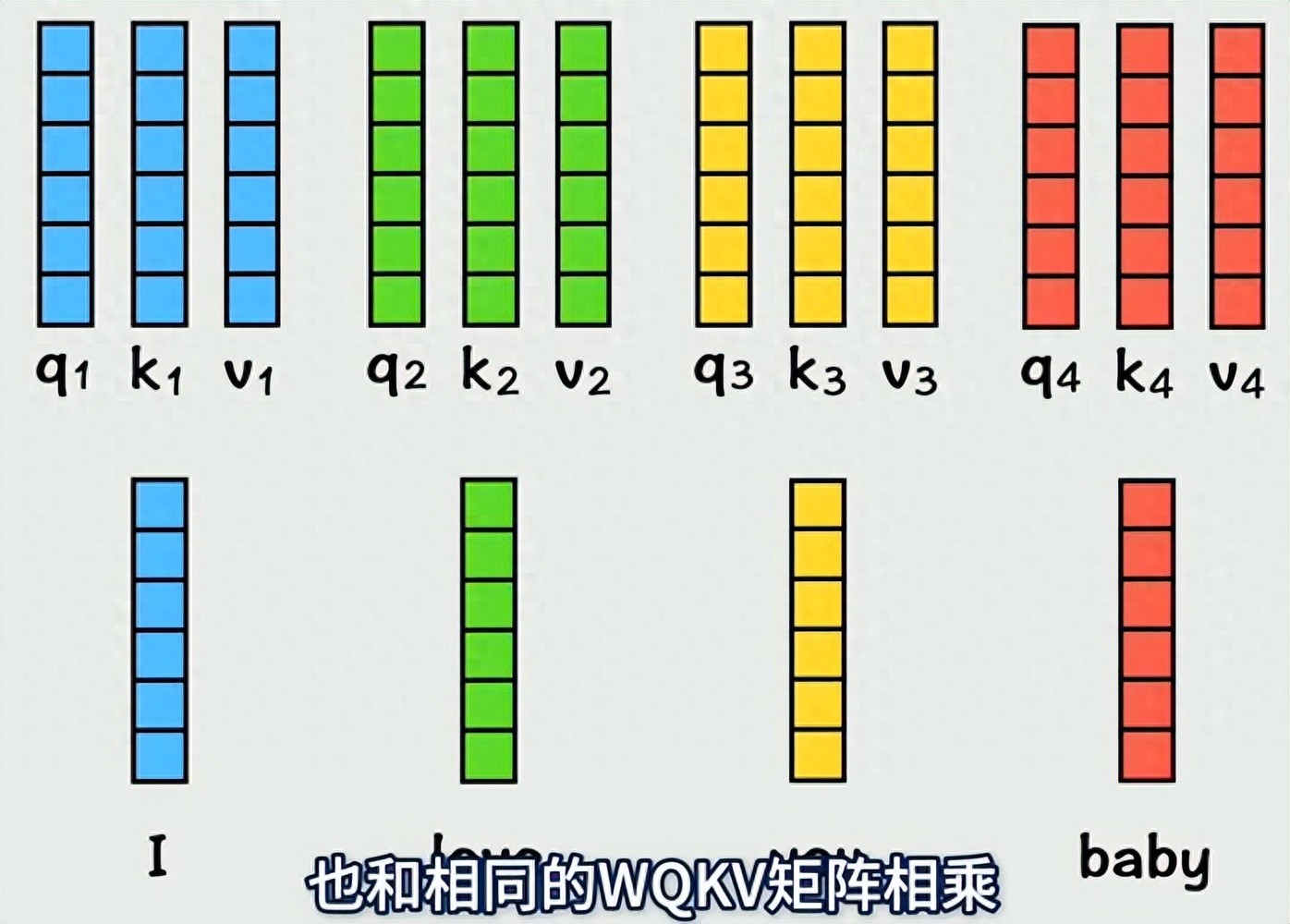
的核心突破在于引入自注意力机制,解决了传统模型处理长序列信息的瓶颈。此前的循环神经网络按顺序处理数据,难以捕捉长距离关联;卷积神经网络擅长局部特征提取,却缺乏全局视角。而自注意力机制让模型能像人类阅读一样,动态计算每个元素与其他所有元素的关联权重,精准捕捉 “上下文语义联系”,哪怕文本长度达到数千字。
从结构上看, 由编码器和解码器两部分组成。编码器负责将输入数据(文字、图像像素等)转化为包含丰富语义信息的向量表示;解码器则基于这些向量生成目标输出(翻译结果、回答内容等)。两者通过 “多头注意力” 机制并行处理数据,彻底摆脱了序列依赖的限制,大幅提升了训练效率。
这一架构的灵活性和高效性使其成为 AI 领域的 “万能基础”。以 GPT、BERT 为代表的大语言模型均基于 构建,推动 AI 从 “专项任务工具” 进化为 “通用智能助手”。如今,其应用已从自然语言处理扩展到图像识别、语音合成、自动驾驶等多个领域,成为支撑 AI 技术快速迭代的核心基础设施。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...